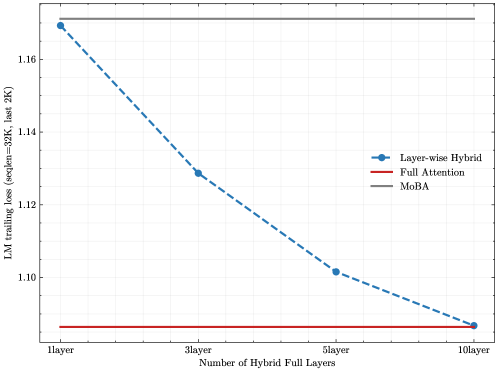
## Line Chart: LM Trailing Loss vs. Number of Hybrid Full Layers
### Overview
The chart compares the performance of three models (Layer-wise Hybrid, Full Attention, MoBA) in terms of language model (LM) trailing loss across different configurations of hybrid full layers. The y-axis represents trailing loss (measured at sequence length 32K, last 2K tokens), while the x-axis categorizes the number of hybrid full layers (1layer, 3layer, 5layer, 10layer). The legend is positioned on the right side of the chart.
### Components/Axes
- **X-axis**: "Number of Hybrid Full Layers" with discrete categories: 1layer, 3layer, 5layer, 10layer.
- **Y-axis**: "LM trailing loss (seqLen=32K, last 2K)" with a scale from 1.10 to 1.16.
- **Legend**:
- Blue dashed line: Layer-wise Hybrid
- Red solid line: Full Attention
- Gray solid line: MoBA
### Detailed Analysis
1. **Layer-wise Hybrid (Blue Dashed Line)**:
- Starts at ~1.17 for 1layer.
- Decreases to ~1.13 at 3layer.
- Further drops to ~1.10 at 5layer.
- Reaches ~1.09 at 10layer.
- **Trend**: Steady downward slope, indicating improved performance with more hybrid layers.
2. **Full Attention (Red Solid Line)**:
- Remains constant at ~1.10 across all configurations.
- **Trend**: Flat line, suggesting no improvement with additional layers.
3. **MoBA (Gray Solid Line)**:
- Maintains a constant value of ~1.16 across all configurations.
- **Trend**: Flat line, indicating no change in performance.
### Key Observations
- **Layer-wise Hybrid** shows the most significant improvement as the number of hybrid layers increases.
- **Full Attention** and **MoBA** exhibit no variation in performance regardless of hybrid layer count.
- The largest gap in performance occurs between Layer-wise Hybrid (1layer) and MoBA (~0.01 difference), narrowing to ~0.07 by 10layer.
### Interpretation
The data suggests that **Layer-wise Hybrid** benefits from increased hybrid full layers, achieving lower trailing loss and potentially better efficiency. In contrast, **Full Attention** and **MoBA** models appear to be optimized for fixed configurations, with no measurable gains from additional layers. This could imply architectural limitations or diminishing returns in these models. The consistent performance of Full Attention and MoBA might indicate robustness in their design but also a lack of adaptability compared to the Layer-wise Hybrid approach.