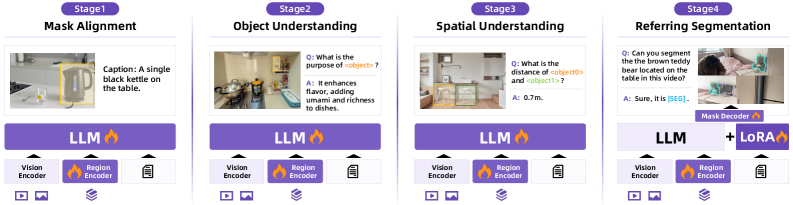
\n
## Diagram: Multimodal LLM Pipeline Stages
### Overview
The image depicts a four-stage pipeline for a multimodal Large Language Model (LLM), showcasing the progression from basic image understanding to complex referring segmentation. Each stage builds upon the previous one, incorporating different components and achieving increasingly sophisticated tasks. The diagram is arranged horizontally, with each stage presented as a distinct block.
### Components/Axes
The diagram consists of four stages labeled "Stage 1", "Stage 2", "Stage 3", and "Stage 4". Each stage has two main sections: an image/question-answer pair at the top and a component diagram at the bottom. The component diagram consistently includes "Vision Encoder", "Region Encoder", and "LLM" (Large Language Model). Stage 4 additionally includes "LoRA" and "Mask Decoder". Icons at the very bottom represent data sources (images, text).
### Detailed Analysis or Content Details
**Stage 1: Mask Alignment**
* **Image:** Shows a kitchen scene with a black kettle on a table.
* **Caption:** "A single black kettle on the table."
* **Components:** Vision Encoder -> Region Encoder -> LLM.
**Stage 2: Object Understanding**
* **Image:** Shows a dining room scene with a table set for a meal.
* **Q:** "What is the purpose of <objects>?"
* **A:** "It enhances flavor, adding umami and richness to dishes."
* **Components:** Vision Encoder -> Region Encoder -> LLM.
**Stage 3: Spatial Understanding**
* **Image:** Shows a room with furniture and a doorway.
* **Q:** "What is the distance of <objects> and <objects>?"
* **A:** "0.7m."
* **Components:** Vision Encoder -> Region Encoder -> LLM.
**Stage 4: Referring Segmentation**
* **Image:** Shows a person holding a brown teddy bear on a table.
* **Q:** "Can you segment the brown teddy bear located on the table in this video?"
* **A:** "Sure, [566]."
* **Components:** Vision Encoder -> Region Encoder -> LLM + LoRA -> Mask Decoder.
The "LLM" component is consistently highlighted with a flame icon. The "Vision Encoder" and "Region Encoder" components also have distinct icons.
### Key Observations
* The complexity of the pipeline increases with each stage. Stage 4 introduces "LoRA" and "Mask Decoder", indicating a more specialized task.
* The questions posed in each stage become progressively more complex, requiring deeper understanding of the image content.
* The consistent presence of "Vision Encoder", "Region Encoder", and "LLM" suggests a core architecture that is augmented with additional components as needed.
* The inclusion of a numerical value "[566]" in Stage 4's answer suggests a segmentation mask or identifier.
### Interpretation
This diagram illustrates a progressive approach to multimodal LLM development. It starts with basic image recognition (mask alignment) and gradually builds towards more sophisticated tasks like object understanding, spatial reasoning, and finally, referring segmentation. The addition of LoRA in Stage 4 suggests a fine-tuning approach to specialize the LLM for the segmentation task. The pipeline demonstrates how different components work together to enable the LLM to "see" and understand images, and then respond to complex queries about them. The flame icon on the LLM component likely signifies its computational intensity or central role in the process. The diagram highlights the increasing complexity of the tasks and the corresponding increase in the number of components required to achieve them. The numerical output in Stage 4 suggests the model is capable of generating precise segmentation masks. This pipeline represents a significant step towards creating AI systems that can interact with the world in a more natural and intuitive way.