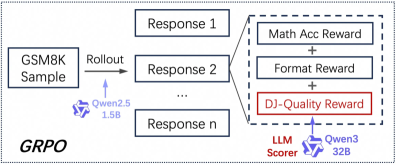
## Diagram: GRPO Method for Multi-Reward Response Evaluation
### Overview
The image is a technical flowchart illustrating a process named **GRPO** (likely an acronym for a reinforcement learning or model training method). The diagram depicts a pipeline that starts with a sample from the GSM8K dataset, generates multiple responses, and evaluates them using a composite reward system involving three distinct reward components. The flow moves from left to right.
### Components/Axes
The diagram is composed of labeled boxes, arrows indicating flow, and text annotations. There are no traditional chart axes.
**1. Left Region (Input & Generation):**
* **Box (Top-Left):** "GSM8K Sample" – This is the input data point.
* **Arrow & Label:** An arrow points right from the "GSM8K Sample" box, labeled "Rollout".
* **Annotation (Below Arrow):** A logo and text "Qwen2.5 1.5B" – This indicates the model used for the "Rollout" (response generation) step is the Qwen2.5 model with 1.5 billion parameters.
* **Text (Bottom-Left Corner):** "GRPO" in large, bold font – This is the name of the overall method or framework being illustrated.
**2. Center Region (Generated Responses):**
* A vertical stack of three boxes, representing multiple outputs from the rollout process.
* **Top Box:** "Response 1"
* **Middle Box:** "Response 2"
* **Bottom Box:** "Response n" – The "n" signifies that an arbitrary number of responses can be generated.
**3. Right Region (Reward Evaluation):**
* A dashed-line rectangle encloses the reward components, indicating they form a unified evaluation module.
* Three boxes are stacked vertically inside this rectangle, connected by plus signs (`+`), suggesting their scores are summed or combined.
* **Top Box (Blue outline):** "Math Acc Reward" – Likely a reward based on mathematical accuracy.
* **Middle Box (Blue outline):** "Format Reward" – A reward for adhering to a required output format.
* **Bottom Box (Red outline):** "DJ-Quality Reward" – A reward for quality, with "DJ" possibly being an acronym for a specific metric or model. This box is highlighted with a red outline, drawing attention to it.
* **Annotation (Below Reward Boxes):** An arrow points up to the "DJ-Quality Reward" box from the text "LLM Scorer" and a logo with text "Qwen3 32B". This specifies that the "DJ-Quality Reward" is computed by a separate, larger language model (Qwen3 with 32 billion parameters) acting as a scorer.
### Detailed Analysis
The process flow is as follows:
1. A sample is taken from the **GSM8K** dataset (a benchmark for grade-school math problems).
2. The **Qwen2.5 1.5B** model performs a "Rollout," generating `n` different candidate responses (`Response 1` to `Response n`) for that sample.
3. Each generated response is evaluated by a composite reward function. This function is the sum of three distinct rewards:
* **Math Acc Reward:** Evaluates correctness of the mathematical solution.
* **Format Reward:** Evaluates structural compliance (e.g., using specific tags or a step-by-step format).
* **DJ-Quality Reward:** Evaluates a broader quality dimension (e.g., reasoning clarity, explanation depth). This specific reward is not computed by the smaller Qwen2.5 model but is instead scored by a much larger **Qwen3 32B** model, which acts as an "LLM Scorer."
### Key Observations
* **Model Hierarchy:** There is a clear two-model architecture. A smaller, efficient model (1.5B) generates candidate responses, while a larger, more powerful model (32B) is used as a judge to provide a sophisticated quality reward.
* **Multi-Faceted Evaluation:** The system doesn't rely on a single metric. It combines accuracy, format, and a separate quality judgment, suggesting a holistic approach to training or evaluating the response generator.
* **Highlighted Component:** The "DJ-Quality Reward" is visually emphasized with a red outline, indicating it may be the novel or most critical component of the GRPO method being presented.
* **Scalability:** The use of "Response n" implies the method is designed to work with a variable number of candidate responses per input sample.
### Interpretation
This diagram outlines a **reinforcement learning from AI feedback (RLAIF)** or **model alignment** pipeline. The GRPO method appears to be a technique for improving a smaller language model (Qwen2.5 1.5B) by generating multiple solutions to math problems and scoring them using a composite reward signal. The key innovation seems to be the integration of a high-quality reward signal ("DJ-Quality") derived from a much larger "teacher" model (Qwen3 32B). This allows the smaller student model to learn not just from simple correctness (Math Acc) and formatting, but also from nuanced quality judgments that only a larger model can reliably provide. The process likely involves using these combined rewards to perform reinforcement learning (e.g., PPO) or best-response selection to fine-tune the Qwen2.5 model, aiming to make it more accurate, well-formatted, and high-quality in its reasoning outputs, particularly for mathematical tasks.