\n
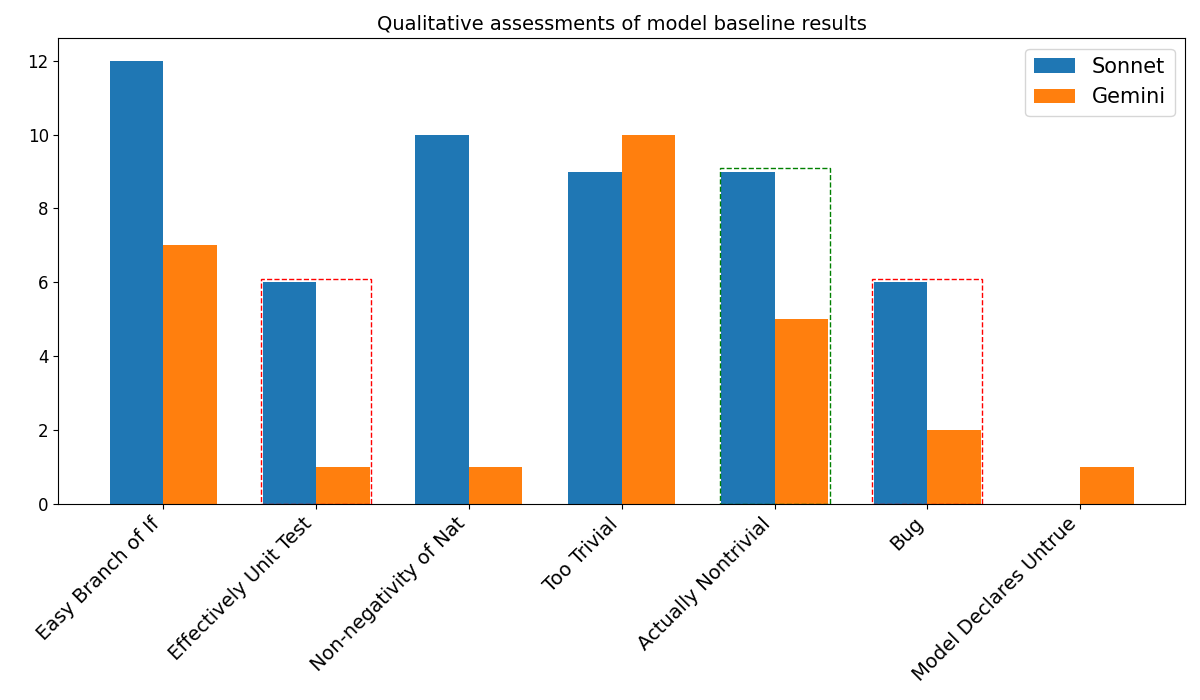
## Bar Chart: Qualitative assessments of model baseline results
### Overview
This bar chart compares the performance of two models, "Sonnet" (blue bars) and "Gemini" (orange bars), across seven different qualitative assessments. The y-axis represents a numerical score, while the x-axis lists the assessment categories. The chart visually displays the relative performance of each model in each category.
### Components/Axes
* **Title:** Qualitative assessments of model baseline results
* **X-axis Label:** Assessment Category
* Categories: "Easy Branch of If", "Effectively Unit Test", "Non-negativity of Nat.", "Too Trivial", "Actually Nontrivial", "Bug", "Model Declares Untrue"
* **Y-axis Label:** Score (Scale from 0 to 12, increments of 2)
* **Legend:**
* Sonnet (Blue)
* Gemini (Orange)
### Detailed Analysis
The chart consists of paired bars for each assessment category, representing the scores for Sonnet and Gemini.
* **Easy Branch of If:** Sonnet scores approximately 12, Gemini scores approximately 7.
* **Effectively Unit Test:** Sonnet scores approximately 10, Gemini scores approximately 6.
* **Non-negativity of Nat.:** Sonnet scores approximately 9.5, Gemini scores approximately 6.
* **Too Trivial:** Sonnet scores approximately 8.5, Gemini scores approximately 9.5.
* **Actually Nontrivial:** Sonnet scores approximately 9, Gemini scores approximately 8.5.
* **Bug:** Sonnet scores approximately 8, Gemini scores approximately 6.
* **Model Declares Untrue:** Sonnet scores approximately 6, Gemini scores approximately 2.
The Sonnet model generally outperforms Gemini in most categories. Gemini shows a slight advantage in the "Too Trivial" category.
### Key Observations
* Sonnet consistently scores higher than Gemini across most assessments.
* The largest performance difference is observed in the "Easy Branch of If" and "Model Declares Untrue" categories.
* The "Too Trivial" category is the only one where Gemini outperforms Sonnet.
* The scores for both models are relatively high, suggesting both models perform reasonably well overall.
### Interpretation
The data suggests that the Sonnet model is generally more robust and accurate than the Gemini model across a range of qualitative assessments. The "Too Trivial" category being an exception suggests Gemini may be better suited for very simple tasks, or that the assessment itself is flawed. The significant difference in "Easy Branch of If" and "Model Declares Untrue" indicates Sonnet is better at handling basic conditional logic and avoiding false positives. The chart provides a comparative performance overview, highlighting the strengths and weaknesses of each model. The assessments themselves are qualitative, so the numerical scores likely represent subjective evaluations. Further investigation into the specific criteria used for each assessment would be beneficial to understand the underlying reasons for the observed performance differences.