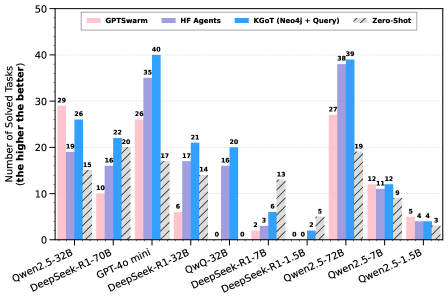
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
The chart compares the performance of various AI models (e.g., Qwen2.5-32B, DeepSeek-R1-70B) across four task-solving methodologies: GPTswarm, HF Agents, KGoT (Neo4j + Query), and Zero-Shot. The y-axis represents the number of tasks solved, while the x-axis lists model names. Each model has four grouped bars corresponding to the methodologies.
### Components/Axes
- **X-Axis (Categories)**: Model names (e.g., Qwen2.5-32B, DeepSeek-R1-70B, GPT-40 mini, etc.).
- **Y-Axis (Scale)**: Number of solved tasks (0–50, increments of 10).
- **Legend**:
- Pink: GPTswarm
- Purple: HF Agents
- Blue: KGoT (Neo4j + Query)
- Gray: Zero-Shot
- **Bar Colors**: Match legend labels (e.g., pink bars for GPTswarm).
### Detailed Analysis
- **Qwen2.5-32B**:
- GPTswarm: 29
- HF Agents: 19
- KGoT: 26
- Zero-Shot: 15
- **DeepSeek-R1-70B**:
- GPTswarm: 10
- HF Agents: 16
- KGoT: 22
- Zero-Shot: 20
- **GPT-40 mini**:
- GPTswarm: 26
- HF Agents: 35
- KGoT: 40
- Zero-Shot: 17
- **DeepSeek-R1-32B**:
- GPTswarm: 6
- HF Agents: 17
- KGoT: 21
- Zero-Shot: 14
- **QwQ-32B**:
- GPTswarm: 0
- HF Agents: 16
- KGoT: 20
- Zero-Shot: 0
- **DeepSeek-R1-7B**:
- GPTswarm: 2
- HF Agents: 3
- KGoT: 6
- Zero-Shot: 13
- **DeepSeek-R1-1.5B**:
- GPTswarm: 0
- HF Agents: 0
- KGoT: 2
- Zero-Shot: 5
- **Qwen2.5-72B**:
- GPTswarm: 27
- HF Agents: 38
- KGoT: 39
- Zero-Shot: 19
- **Qwen2.5-7B**:
- GPTswarm: 12
- HF Agents: 11
- KGoT: 12
- Zero-Shot: 9
- **Qwen2.5-1.5B**:
- GPTswarm: 5
- HF Agents: 4
- KGoT: 4
- Zero-Shot: 3
### Key Observations
1. **KGoT (Neo4j + Query)** consistently outperforms other methods in most models (e.g., 40 for GPT-40 mini, 39 for Qwen2.5-72B).
2. **Zero-Shot** generally has the lowest performance across models (e.g., 3 for Qwen2.5-1.5B).
3. **HF Agents** show strong performance in larger models (e.g., 35 for GPT-40 mini, 38 for Qwen2.5-72B).
4. **GPTswarm** excels in mid-to-large models (e.g., 29 for Qwen2.5-32B, 27 for Qwen2.5-72B).
5. Smaller models (e.g., DeepSeek-R1-1.5B) have minimal task-solving capacity across all methods.
### Interpretation
The data suggests that **KGoT (Neo4j + Query)** and **GPTswarm** are the most effective methodologies for solving tasks, particularly in larger models. **HF Agents** perform well in larger models but struggle with smaller ones. **Zero-Shot** underperforms universally, indicating its limitations without task-specific tuning. The disparity between methodologies highlights the importance of hybrid approaches (e.g., KGoT) for complex tasks. Outliers like QwQ-32B (all zeros for GPTswarm and Zero-Shot) suggest potential data anomalies or model-specific constraints.