\n
## Grouped Bar Chart: Model Accuracy Comparison on ARC-C and MATH Tasks
### Overview
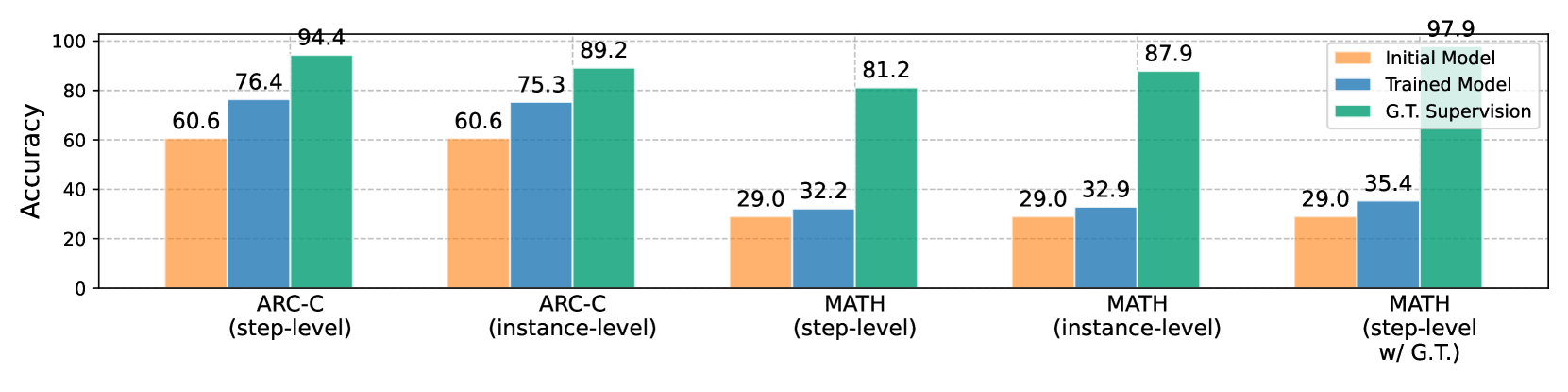
The image displays a grouped bar chart comparing the accuracy percentages of three different model types ("Initial Model," "Trained Model," and "G.T. Supervision") across five distinct evaluation settings related to the ARC-C and MATH benchmarks. The chart clearly demonstrates the performance hierarchy and the impact of training and ground truth supervision.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Accuracy." The scale runs from 0 to 100 in increments of 20, with horizontal grid lines at these intervals.
* **X-Axis:** Contains five categorical groups representing different evaluation tasks:
1. ARC-C (step-level)
2. ARC-C (instance-level)
3. MATH (step-level)
4. MATH (instance-level)
5. MATH (step-level w/ G.T.)
* **Legend:** Positioned in the top-right corner of the chart area. It defines the three data series:
* **Initial Model:** Represented by orange bars.
* **Trained Model:** Represented by blue bars.
* **G.T. Supervision:** Represented by green bars. ("G.T." likely stands for "Ground Truth").
### Detailed Analysis
The chart presents the following specific accuracy values for each model in each task category:
**1. ARC-C (step-level)**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 76.4
* G.T. Supervision (Green): 94.4
**2. ARC-C (instance-level)**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 75.3
* G.T. Supervision (Green): 89.2
**3. MATH (step-level)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.2
* G.T. Supervision (Green): 81.2
**4. MATH (instance-level)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.9
* G.T. Supervision (Green): 87.9
**5. MATH (step-level w/ G.T.)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 35.4
* G.T. Supervision (Green): 97.9
### Key Observations
1. **Consistent Performance Hierarchy:** In every single task category, the "G.T. Supervision" model (green) achieves the highest accuracy, followed by the "Trained Model" (blue), with the "Initial Model" (orange) performing the worst.
2. **Task Difficulty Disparity:** There is a stark contrast in baseline performance between ARC-C and MATH tasks. The "Initial Model" scores ~60.6% on ARC-C tasks but only 29.0% on all MATH tasks, indicating MATH is a significantly more challenging benchmark for the base model.
3. **Impact of Training:** Training ("Trained Model") provides a substantial accuracy boost over the "Initial Model" on ARC-C tasks (+15.8 and +14.7 percentage points). The improvement on MATH tasks is much smaller (+3.2, +3.9, and +6.4 percentage points).
4. **Dominance of Ground Truth Supervision:** The "G.T. Supervision" model shows dramatic performance gains, especially on the difficult MATH tasks. Its accuracy on "MATH (step-level w/ G.T.)" reaches 97.9%, nearly perfect performance.
5. **Instance vs. Step-level:** For ARC-C, step-level evaluation yields slightly higher accuracy for G.T. Supervision (94.4 vs. 89.2). For MATH, the pattern is less clear, with instance-level (87.9) outperforming step-level (81.2) for G.T. Supervision, but step-level with G.T. (97.9) being the highest overall.
### Interpretation
This chart illustrates a clear narrative about model capability and the value of supervision. The data suggests that:
* **The core reasoning ability (Initial Model) is insufficient for complex mathematical problems,** as evidenced by the low 29% baseline on MATH versus ~60% on ARC-C.
* **Standard training provides moderate improvements,** but is particularly limited in elevating performance on the hardest tasks (MATH).
* **Access to ground truth (G.T. Supervision) is the most critical factor for high performance,** enabling near-perfect scores even on the most difficult task variant. This implies that the model's underlying architecture may be capable, but it relies heavily on correct guidance or supervision to apply that capability effectively.
* The **"MATH (step-level w/ G.T.)"** result (97.9%) is a key outlier, demonstrating a ceiling effect when the model is provided with perfect intermediate steps. This highlights a potential pathway for improving model performance: not just training on final answers, but on the correctness of the reasoning process itself.
The chart effectively argues that while training helps, the provision of ground truth supervision—particularly at the step-level for complex problems—is the dominant driver of high accuracy in these evaluations.