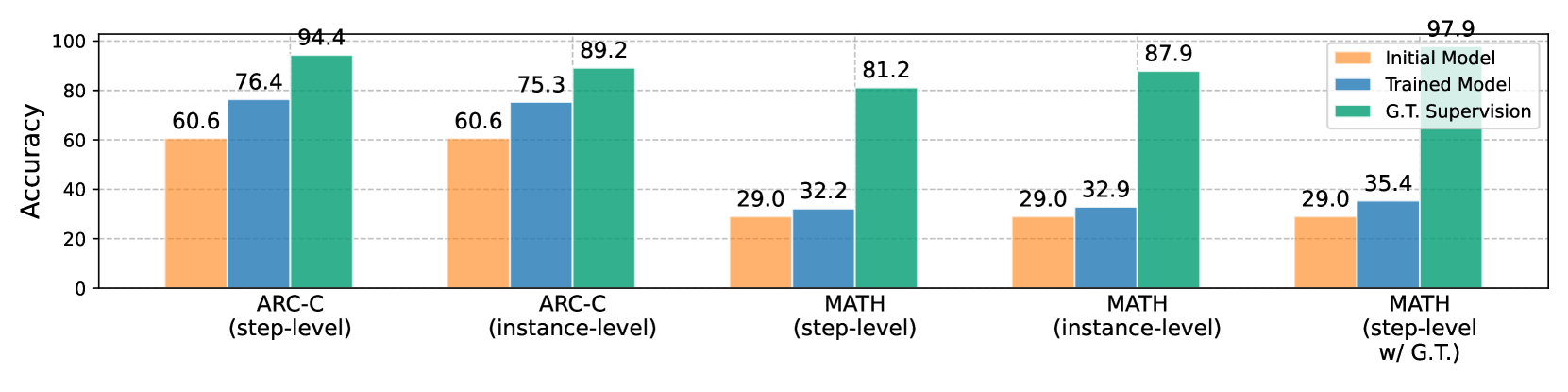
## Bar Chart: Model Accuracy Comparison Across Tasks and Evaluation Levels
### Overview
The chart compares accuracy percentages of three models (Initial Model, Trained Model, G.T. Supervision) across two tasks (ARC-C, MATH) and two evaluation levels (step-level, instance-level). A fifth category combines MATH step-level with ground truth supervision (G.T.). The y-axis represents accuracy (0-100%), while the x-axis categorizes tasks and evaluation types.
### Components/Axes
- **X-axis**:
- Categories:
1. ARC-C (step-level)
2. ARC-C (instance-level)
3. MATH (step-level)
4. MATH (instance-level)
5. MATH (step-level w/ G.T.)
- **Y-axis**: Accuracy (0-100%, increments of 20)
- **Legend**:
- Orange: Initial Model
- Blue: Trained Model
- Green: G.T. Supervision
- **Bar Values**: Numerical accuracy percentages displayed atop each bar.
### Detailed Analysis
1. **ARC-C (step-level)**:
- Initial Model: 60.6%
- Trained Model: 76.4%
- G.T. Supervision: 94.4%
2. **ARC-C (instance-level)**:
- Initial Model: 60.6%
- Trained Model: 75.3%
- G.T. Supervision: 89.2%
3. **MATH (step-level)**:
- Initial Model: 29.0%
- Trained Model: 32.2%
- G.T. Supervision: 81.2%
4. **MATH (instance-level)**:
- Initial Model: 29.0%
- Trained Model: 32.9%
- G.T. Supervision: 87.9%
5. **MATH (step-level w/ G.T.)**:
- Initial Model: 29.0%
- Trained Model: 35.4%
- G.T. Supervision: 97.9%
### Key Observations
- **G.T. Supervision Dominance**: Green bars (G.T. Supervision) consistently show the highest accuracy across all categories, reaching 97.9% in MATH step-level with G.T.
- **Trained Model vs. Initial Model**: Blue bars (Trained Model) outperform orange bars (Initial Model) in all cases, with the largest gap in MATH step-level w/ G.T. (35.4% vs. 29.0%).
- **Task-Specific Trends**:
- ARC-C tasks show higher baseline accuracy than MATH tasks.
- Instance-level evaluations for ARC-C slightly underperform step-level (e.g., 89.2% vs. 94.4% for G.T. Supervision).
- MATH instance-level accuracy surpasses step-level for G.T. Supervision (87.9% vs. 81.2%).
### Interpretation
The data demonstrates that **ground truth supervision (G.T.) is critical for high accuracy**, particularly in complex tasks like MATH. The Trained Model improves upon the Initial Model but remains significantly outperformed by G.T. supervision. Notably, MATH step-level with G.T. achieves near-perfect accuracy (97.9%), suggesting that combining step-level evaluation with ground truth yields optimal results. The disparity between Initial and Trained Models highlights the value of model training, while the consistent G.T. superiority underscores its role as a benchmark. The instance-level vs. step-level performance differences may reflect task complexity or evaluation methodology nuances.