\n
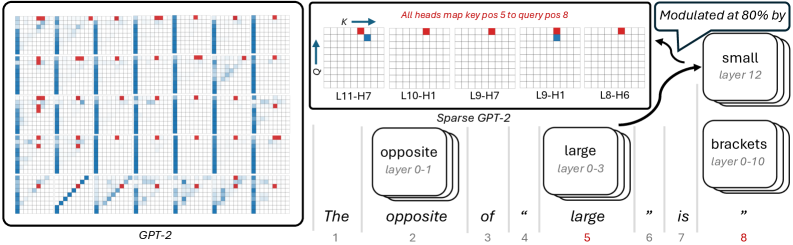
## Diagram: Sparse GPT-2 Attention Map & Layer Relationships
### Overview
The image presents a diagram illustrating the attention mechanism within the GPT-2 model, specifically focusing on a sparse variant. It depicts attention maps for different layers and highlights relationships between layers described as "opposite" and "large". The diagram uses a grid-based representation of attention weights, with color indicating the strength of attention.
### Components/Axes
The diagram is composed of several key elements:
* **GPT-2 Attention Map (Left):** A large grid representing the attention weights within the GPT-2 model. The grid is composed of vertical lines, with red squares indicating attention points.
* **Sparse GPT-2 Attention Map (Top-Right):** A smaller grid representing attention weights in a sparse GPT-2 model. It has labels for layers (L11-H7, L10-H1, L9-H7, L9-H1, L8-H6) and axes labeled 'K' and 'Q'.
* **Layer Blocks (Bottom):** Three stacked blocks representing different layers: "opposite layer 0-1", "large layer 0-3", and "brackets layer 0-10".
* **Textual Description (Bottom):** The phrase "The opposite of “large” is “".
* **Annotation:** "Modulated at 80% by" with an arrow pointing from the Sparse GPT-2 Attention Map to a "small layer 12" block.
The axes in the Sparse GPT-2 Attention Map are labeled 'K' (vertical) and 'Q' (horizontal).
### Detailed Analysis or Content Details
**GPT-2 Attention Map (Left):**
* The grid is approximately 15x15.
* Vertical lines dominate the grid, indicating a strong attention pattern along the sequence length.
* Red squares are sparsely distributed throughout the grid, indicating attention points. The density of red squares appears to vary across the grid.
* The pattern is somewhat diagonal, with attention points clustered along certain diagonals.
**Sparse GPT-2 Attention Map (Top-Right):**
* The grid is approximately 8x8.
* The layers are labeled as follows: L11-H7, L10-H1, L9-H7, L9-H1, L8-H6.
* The 'K' axis appears to represent the key dimension, and the 'Q' axis represents the query dimension.
* Red squares are present, indicating attention weights. The distribution of red squares appears relatively sparse.
* The annotation "Modulated at 80% by" points to a "small layer 12" block.
**Layer Blocks (Bottom):**
* "opposite layer 0-1"
* "large layer 0-3"
* "brackets layer 0-10"
**Textual Description (Bottom):**
* "The opposite of “large” is “"
### Key Observations
* The attention maps show a sparse attention pattern, meaning that not all tokens attend to all other tokens.
* The "large" and "opposite" layers are explicitly mentioned, suggesting a specific architectural feature or relationship within the model.
* The modulation at 80% indicates a scaling or weighting applied to the attention mechanism.
* The layer ranges (0-1, 0-3, 0-10) suggest different depths or spans within the model.
### Interpretation
The diagram illustrates a sparse attention mechanism in GPT-2, where attention is focused on a subset of tokens rather than all tokens. The "large" and "opposite" layers likely represent different components of the attention mechanism, potentially related to long-range dependencies and local context, respectively. The modulation at 80% suggests a form of regularization or control over the attention weights. The diagram highlights the hierarchical structure of the model, with different layers contributing to the overall attention pattern. The incomplete sentence "The opposite of “large” is “" suggests a conceptual relationship being explored, potentially hinting at a contrasting attention pattern or function. The diagram is likely used to explain or visualize a specific architectural modification or analysis of the GPT-2 model. The use of sparse attention is a common technique to reduce computational cost and improve efficiency in large language models. The diagram suggests that the model is being analyzed or modified to understand the role of different layers and attention patterns.