TECHNICAL ASSET FINGERPRINT
ae8c74470525a9b1809c5d8f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
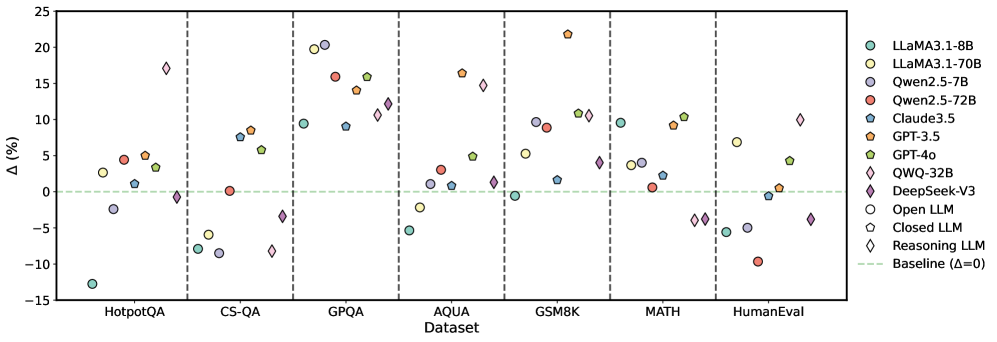
## Scatter Plot: Model Performance Across Datasets
### Overview
The image is a scatter plot comparing the performance of various language models (LLMs) across different datasets. The y-axis represents the change in performance (Δ in percentage), and the x-axis represents the datasets. Each model is represented by a unique color and shape combination, as indicated in the legend on the right. A horizontal dashed green line indicates the baseline performance (Δ=0).
### Components/Axes
* **X-axis:** Datasets: HotpotQA, CS-QA, GPQA, AQUA, GSM8K, MATH, HumanEval.
* **Y-axis:** Δ (%), ranging from -15% to 25% with increments of 5%.
* **Legend (Right side):**
* Light Blue Circle: LLaMA3.1-8B
* Yellow Circle: LLaMA3.1-70B
* Dark Blue Circle: Qwen2.5-7B
* Red Circle: Qwen2.5-72B
* Blue Pentagon: Claude3.5
* Orange Pentagon: GPT-3.5
* Green Pentagon: GPT-4o
* Purple Diamond: QWQ-32B
* Dark Purple Diamond: DeepSeek-V3
* White Circle: Open LLM
* White Pentagon: Closed LLM
* White Diamond: Reasoning LLM
* Green Dashed Line: Baseline (Δ=0)
### Detailed Analysis
**HotpotQA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately -13%
* LLaMA3.1-70B (Yellow Circle): Approximately 5%
* Qwen2.5-7B (Dark Blue Circle): Approximately -2%
* Qwen2.5-72B (Red Circle): Approximately 5%
* Claude3.5 (Blue Pentagon): Approximately 5%
* GPT-3.5 (Orange Pentagon): Approximately 5%
* GPT-4o (Green Pentagon): Approximately 3%
* QWQ-32B (Purple Diamond): Approximately -1%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -1%
* Open LLM (White Circle): Approximately -3%
* Closed LLM (White Pentagon): Approximately -8%
* Reasoning LLM (White Diamond): Approximately -1%
**CS-QA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately -8%
* LLaMA3.1-70B (Yellow Circle): Approximately -6%
* Qwen2.5-7B (Dark Blue Circle): Approximately -9%
* Qwen2.5-72B (Red Circle): Approximately 8%
* Claude3.5 (Blue Pentagon): Approximately 8%
* GPT-3.5 (Orange Pentagon): Approximately 8%
* GPT-4o (Green Pentagon): Approximately 1%
* QWQ-32B (Purple Diamond): Approximately 11%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -1%
* Open LLM (White Circle): Approximately -1%
* Closed LLM (White Pentagon): Approximately -1%
* Reasoning LLM (White Diamond): Approximately -1%
**GPQA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 1%
* LLaMA3.1-70B (Yellow Circle): Approximately 15%
* Qwen2.5-7B (Dark Blue Circle): Approximately 1%
* Qwen2.5-72B (Red Circle): Approximately 17%
* Claude3.5 (Blue Pentagon): Approximately 15%
* GPT-3.5 (Orange Pentagon): Approximately 20%
* GPT-4o (Green Pentagon): Approximately 4%
* QWQ-32B (Purple Diamond): Approximately 12%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 17%
* Open LLM (White Circle): Approximately -5%
* Closed LLM (White Pentagon): Approximately -1%
* Reasoning LLM (White Diamond): Approximately 11%
**AQUA Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 2%
* LLaMA3.1-70B (Yellow Circle): Approximately 1%
* Qwen2.5-7B (Dark Blue Circle): Approximately 3%
* Qwen2.5-72B (Red Circle): Approximately 4%
* Claude3.5 (Blue Pentagon): Approximately 1%
* GPT-3.5 (Orange Pentagon): Approximately 5%
* GPT-4o (Green Pentagon): Approximately 2%
* QWQ-32B (Purple Diamond): Approximately 11%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -1%
* Open LLM (White Circle): Approximately 1%
* Closed LLM (White Pentagon): Approximately 1%
* Reasoning LLM (White Diamond): Approximately 1%
**GSM8K Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 11%
* LLaMA3.1-70B (Yellow Circle): Approximately 10%
* Qwen2.5-7B (Dark Blue Circle): Approximately 11%
* Qwen2.5-72B (Red Circle): Approximately 10%
* Claude3.5 (Blue Pentagon): Approximately 11%
* GPT-3.5 (Orange Pentagon): Approximately 10%
* GPT-4o (Green Pentagon): Approximately 11%
* QWQ-32B (Purple Diamond): Approximately 11%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 4%
* Open LLM (White Circle): Approximately 1%
* Closed LLM (White Pentagon): Approximately 1%
* Reasoning LLM (White Diamond): Approximately 1%
**MATH Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 3%
* LLaMA3.1-70B (Yellow Circle): Approximately 3%
* Qwen2.5-7B (Dark Blue Circle): Approximately 3%
* Qwen2.5-72B (Red Circle): Approximately 3%
* Claude3.5 (Blue Pentagon): Approximately 3%
* GPT-3.5 (Orange Pentagon): Approximately 3%
* GPT-4o (Green Pentagon): Approximately 3%
* QWQ-32B (Purple Diamond): Approximately 3%
* DeepSeek-V3 (Dark Purple Diamond): Approximately -4%
* Open LLM (White Circle): Approximately -6%
* Closed LLM (White Pentagon): Approximately -6%
* Reasoning LLM (White Diamond): Approximately -4%
**HumanEval Dataset:**
* LLaMA3.1-8B (Light Blue Circle): Approximately 4%
* LLaMA3.1-70B (Yellow Circle): Approximately 5%
* Qwen2.5-7B (Dark Blue Circle): Approximately 4%
* Qwen2.5-72B (Red Circle): Approximately 4%
* Claude3.5 (Blue Pentagon): Approximately 4%
* GPT-3.5 (Orange Pentagon): Approximately 4%
* GPT-4o (Green Pentagon): Approximately 4%
* QWQ-32B (Purple Diamond): Approximately 4%
* DeepSeek-V3 (Dark Purple Diamond): Approximately 1%
* Open LLM (White Circle): Approximately 1%
* Closed LLM (White Pentagon): Approximately 1%
* Reasoning LLM (White Diamond): Approximately 1%
### Key Observations
* The performance of different models varies significantly across different datasets.
* GPT-3.5 generally performs well across all datasets, often achieving high scores.
* LLaMA3.1-8B shows the lowest performance on HotpotQA.
* Reasoning LLM shows the lowest performance on MATH.
* The performance of Open LLM and Closed LLM is consistently low across all datasets.
### Interpretation
The scatter plot provides a comparative analysis of various language models' performance on different datasets. The variation in performance highlights the strengths and weaknesses of each model in handling different types of tasks. For example, GPT-3.5 consistently performs well, indicating its robustness across different tasks, while LLaMA3.1-8B struggles with HotpotQA. The plot also reveals that certain models, like Open LLM and Closed LLM, consistently underperform compared to others. This information is valuable for selecting the most appropriate model for a specific task and for identifying areas where model improvement is needed. The "Reasoning LLM" models (marked with diamonds) show a wide range of performance, suggesting that reasoning ability is highly task-dependent.
DECODING INTELLIGENCE...