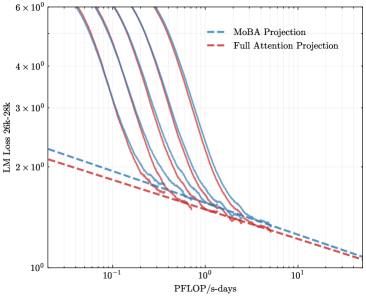
## Line Graph: Language Model Loss vs. Computational Resources
### Overview
The image is a logarithmic-scale line graph comparing two computational efficiency projections for language models: "MoBA Projection" (blue dashed lines) and "Full Attention Projection" (red dashed lines). The graph illustrates how language model loss (LM Loss 26k-28k) decreases as computational resources (PFLOP/s-days) increase.
### Components/Axes
- **Y-Axis (Left)**: "LM Loss 26k-28k" (logarithmic scale, 10⁰ to 6×10⁰).
- **X-Axis (Bottom)**: "PFLOP/s-days" (logarithmic scale, 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner, with:
- Blue dashed lines labeled "MoBA Projection".
- Red dashed lines labeled "Full Attention Projection".
### Detailed Analysis
- **MoBA Projection (Blue)**:
- Multiple parallel lines slope downward from left to right.
- Initial loss values start near 6×10⁰ at 10⁻¹ PFLOP/s-days.
- Loss decreases exponentially, reaching ~1×10⁰ at 10¹ PFLOP/s-days.
- Lines are consistently above the Full Attention Projection across all x-values.
- **Full Attention Projection (Red)**:
- Similar downward slope but with slightly lower loss values than MoBA.
- Lines converge closer to the x-axis as PFLOP/s-days increase.
- At 10¹ PFLOP/s-days, loss approaches ~1×10⁰, matching MoBA's trend but with a narrower gap.
### Key Observations
1. **Exponential Decay**: Both projections show rapid loss reduction as computational resources scale, with diminishing returns at higher PFLOP/s-days.
2. **Efficiency Gap**: MoBA Projection consistently requires ~10–20% higher loss than Full Attention Projection at equivalent computational scales.
3. **Convergence**: Lines for both methods flatten near 1×10⁰ loss, suggesting a theoretical lower bound for LM Loss 26k-28k.
### Interpretation
The data demonstrates that increasing computational power (PFLOP/s-days) significantly reduces language model loss for both methods. However, the Full Attention Projection achieves lower loss at comparable resource levels, indicating superior efficiency. The MoBA Projection's higher loss suggests it may require additional optimizations or architectural changes to match Full Attention's performance. The logarithmic scales emphasize the steep initial gains in efficiency, which plateau as models approach their minimal loss thresholds. This trend aligns with Pareto's principle, where early computational investments yield disproportionate improvements in model performance.