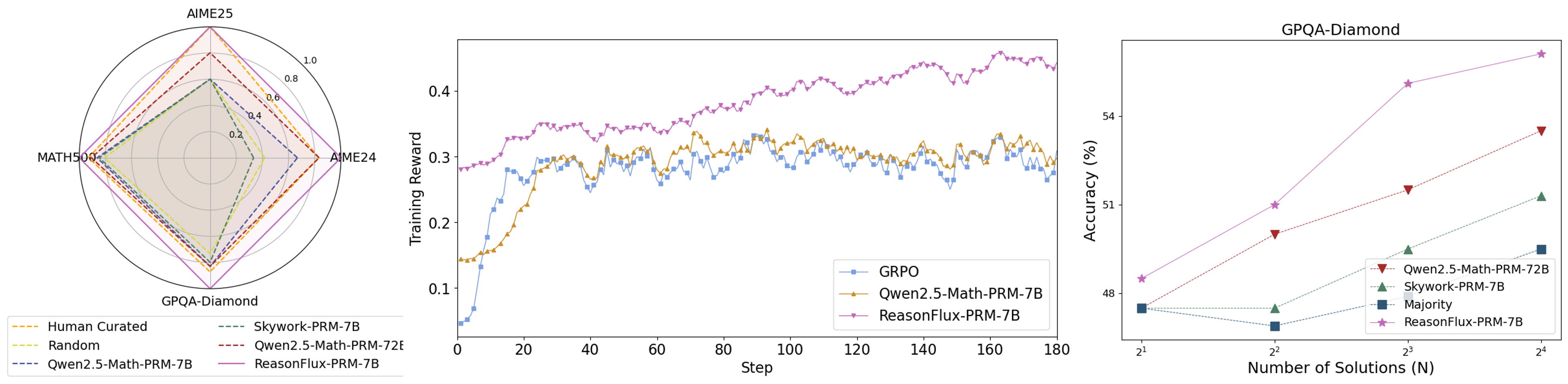
## Radar Chart: Model Performance Across Benchmarks
### Overview
A radar chart comparing model performance across four benchmarks: AIME25, MATH500, GPQA-Diamond, and AIME24. Five data series are represented with distinct line styles and colors.
### Components/Axes
- **Axes**:
- Top: AIME25
- Left: MATH500
- Bottom: GPQA-Diamond
- Right: AIME24
- **Legend**:
- Orange dashed: Human Curated
- Dashed green: Skywork-PRM-7B
- Dotted yellow: Random
- Solid red: Qwen2.5-Math-PRM-7B
- Solid purple: ReasonFlux-PRM-7B
- **Scale**: 0.0 to 1.0 (outer ring)
### Detailed Analysis
- **Human Curated** (orange dashed): Outermost polygon, consistently highest values (~0.8–1.0 across all axes).
- **ReasonFlux-PRM-7B** (solid purple): Second-largest polygon, values ~0.6–0.9.
- **Qwen2.5-Math-PRM-7B** (solid red): Third-largest, values ~0.5–0.8.
- **Skywork-PRM-7B** (dashed green): Values ~0.4–0.7.
- **Random** (dotted yellow): Innermost polygon, values ~0.2–0.5.
### Key Observations
- Human Curated dominates all benchmarks, suggesting it represents a human performance baseline.
- ReasonFlux-PRM-7B consistently outperforms Qwen2.5-Math-PRM-7B and Skywork-PRM-7B.
- Random performs significantly worse than all trained models.
### Interpretation
The radar chart demonstrates that ReasonFlux-PRM-7B achieves the closest performance to the human-curated benchmark across all tasks, while Qwen2.5-Math-PRM-7B and Skywork-PRM-7B show moderate performance. The Random baseline highlights the effectiveness of the models compared to chance.
---
## Line Graph: Training Reward Over Steps
### Overview
A line graph tracking training reward over 180 steps for three models: GRPO, Qwen2.5-Math-PRM-7B, and ReasonFlux-PRM-7B.
### Components/Axes
- **X-axis**: Steps (0 to 180)
- **Y-axis**: Training Reward (0.1 to 0.4)
- **Legend**:
- Blue squares: GRPO
- Orange triangles: Qwen2.5-Math-PRM-7B
- Purple stars: ReasonFlux-PRM-7B
### Detailed Analysis
- **ReasonFlux-PRM-7B** (purple stars):
- Starts at ~0.28, peaks at ~0.42 by step 180.
- Smooth upward trend with minor fluctuations.
- **Qwen2.5-Math-PRM-7B** (orange triangles):
- Begins at ~0.15, reaches ~0.32 by step 180.
- Noisy with oscillations but generally increasing.
- **GRPO** (blue squares):
- Starts at ~0.05, rises to ~0.30 by step 180.
- Steeper initial growth but plateaus earlier.
### Key Observations
- ReasonFlux-PRM-7B achieves the highest final reward and maintains stability.
- Qwen2.5-Math-PRM-7B shows moderate performance with higher volatility.
- GRPO improves rapidly but lags behind the other two models in final reward.
### Interpretation
The graph indicates that ReasonFlux-PRM-7B has the most stable and effective training dynamics, while Qwen2.5-Math-PRM-7B and GRPO exhibit trade-offs between growth speed and stability.
---
## Scatter Plot: Accuracy vs. Number of Solutions (GPQA-Diamond)
### Overview
A scatter plot showing accuracy (%) against the number of solutions (N = 2¹ to 2⁴) for four models.
### Components/Axes
- **X-axis**: Number of Solutions (N) (2¹ to 2⁴)
- **Y-axis**: Accuracy (%) (48% to 54%)
- **Legend**:
- Red triangles: Qwen2.5-Math-PRM-7B
- Green dashed: Skywork-PRM-7B
- Blue squares: Majority
- Purple stars: ReasonFlux-PRM-7B
### Detailed Analysis
- **ReasonFlux-PRM-7B** (purple stars):
- Accuracy increases from ~48% (N=2¹) to ~54% (N=2⁴).
- Steep upward trend.
- **Qwen2.5-Math-PRM-7B** (red triangles):
- Accuracy rises from ~48% to ~53%.
- Slightly less steep than ReasonFlux.
- **Skywork-PRM-7B** (green dashed):
- Accuracy increases from ~48% to ~51%.
- Flatter growth.
- **Majority** (blue squares):
- Flat line at ~48% across all N values.
### Key Observations
- ReasonFlux-PRM-7B shows the strongest improvement with more solutions.
- Majority baseline remains constant, indicating no inherent model capability beyond random guessing.
- Qwen2.5-Math-PRM-7B and Skywork-PRM-7B show moderate gains.
### Interpretation
The scatter plot reveals that ReasonFlux-PRM-7B scales most effectively with increased computational resources (solutions), suggesting superior architectural efficiency. The Majority baseline underscores the importance of model training over brute-force methods.
---
## Cross-Referenced Trends
1. **Consistency Across Metrics**: ReasonFlux-PRM-7B outperforms all models in the radar chart, line graph, and scatter plot.
2. **Training Dynamics**: ReasonFlux-PRM-7B achieves higher rewards faster and more stably than Qwen2.5-Math-PRM-7B and GRPO.
3. **Scalability**: ReasonFlux-PRM-7B benefits most from increased solution counts (N), indicating better generalization.
## Conclusion
The data collectively demonstrates that ReasonFlux-PRM-7B is the most performant model across training stability, benchmark accuracy, and scalability. Qwen2.5-Math-PRM-7B and Skywork-PRM-7B show moderate performance, while GRPO and Majority lag behind. Human Curated remains the gold standard, but ReasonFlux-PRM-7B approaches it most closely.