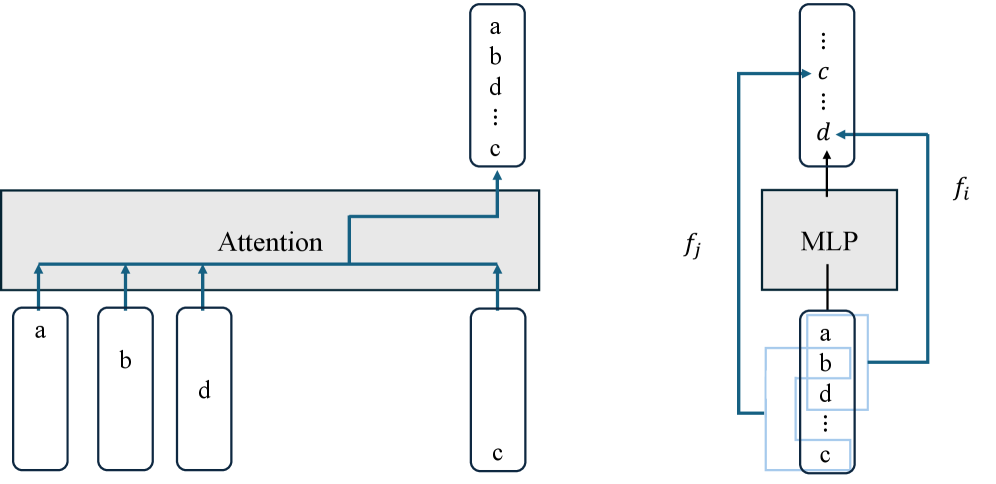
## Diagram: Attention Mechanism and MLP Architecture
### Overview
The image depicts two interconnected components: an **Attention** mechanism on the left and a **Multilayer Perceptron (MLP)** on the right. Arrows indicate data flow between elements, with labels (a, b, c, d) representing input/output nodes.
### Components/Axes
- **Left Diagram (Attention)**:
- A horizontal gray rectangle labeled "Attention" with four vertical arrows pointing to labeled boxes:
- **a**, **b**, **d**, **c** (in that order).
- A vertical list above the rectangle contains the same labels: **a**, **b**, **d**, **c** (top to bottom).
- **Right Diagram (MLP)**:
- A vertical list labeled **a**, **b**, **d**, **c** (top to bottom).
- Arrows from the list point to **c** and **d**, which connect to a gray box labeled **fj**.
- **fj** feeds into another box labeled **fi**.
- The MLP is explicitly labeled, with inputs **a**, **b**, **d**, **c** and outputs **c**, **d**.
### Detailed Analysis
- **Attention Mechanism**:
- Inputs **a**, **b**, **d**, **c** are processed sequentially. The vertical list above the "Attention" box suggests these elements are prioritized or weighted in the order shown.
- **MLP**:
- The MLP takes the same inputs (**a**, **b**, **d**, **c**) and produces outputs **c** and **d**. These outputs are then used as inputs for **fj** and **fi**.
- The MLP’s role appears to be transforming the attention-processed data into intermediate representations (**fj**) and final outputs (**fi**).
### Key Observations
1. **Data Flow**:
- The attention mechanism processes inputs in the order **a → b → d → c**, while the MLP processes them in the same sequence.
- Outputs **c** and **d** from the MLP are critical for downstream tasks (e.g., **fj** and **fi**).
2. **Label Consistency**:
- Labels **a**, **b**, **c**, **d** are reused across both diagrams, suggesting shared input/output semantics.
3. **Structural Hierarchy**:
- The attention mechanism precedes the MLP, implying a two-stage processing pipeline.
### Interpretation
This diagram illustrates a neural network architecture where:
- **Attention** selectively focuses on input elements (**a**, **b**, **d**, **c**) to prioritize relevant information.
- The **MLP** then processes these prioritized inputs to generate intermediate (**fj**) and final (**fi**) outputs.
- The reuse of labels (**a**, **b**, **c**, **d**) across both components suggests modularity, with the MLP acting as a downstream processor for attention-derived features.
The architecture emphasizes hierarchical processing, where attention mechanisms refine input relevance before deeper layers (MLP) perform complex transformations. This pattern is common in tasks like sequence modeling or feature extraction, where early stages filter noise and later stages learn higher-level representations.