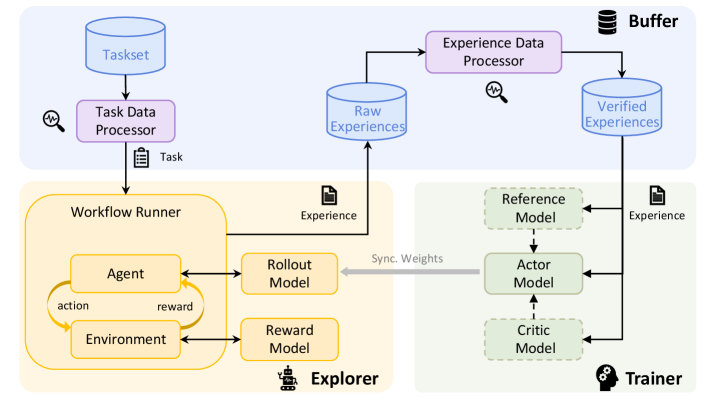
## Diagram: Reinforcement Learning Workflow
### Overview
The image presents a diagram of a reinforcement learning workflow. It illustrates the flow of data and processes between different components, including task management, experience generation, and model training.
### Components/Axes
The diagram is divided into several key components:
* **Taskset:** A blue cylinder at the top-left, representing a collection of tasks.
* **Task Data Processor:** A purple rectangle below the Taskset, responsible for processing task data.
* **Raw Experiences:** A blue cylinder, representing the raw experiences collected during the learning process.
* **Experience Data Processor:** A purple rectangle, responsible for processing experience data.
* **Verified Experiences:** A blue cylinder, representing the verified experiences after processing.
* **Workflow Runner:** A yellow region containing the Agent, Environment, Rollout Model, and Reward Model.
* **Agent:** A rounded rectangle within the Workflow Runner, representing the learning agent.
* **Environment:** A rounded rectangle within the Workflow Runner, representing the environment in which the agent interacts.
* **Rollout Model:** A yellow rounded rectangle to the right of the Agent, used for generating rollouts.
* **Reward Model:** A yellow rounded rectangle below the Rollout Model, used for providing rewards.
* **Explorer:** The yellow region containing the Workflow Runner, Rollout Model, and Reward Model.
* **Buffer:** A stack of cylinders at the top-right, representing a buffer for storing experiences.
* **Trainer:** A green region containing the Reference Model, Actor Model, and Critic Model.
* **Reference Model:** A green dashed rounded rectangle within the Trainer.
* **Actor Model:** A green solid rounded rectangle within the Trainer, representing the policy network.
* **Critic Model:** A green dashed rounded rectangle within the Trainer, representing the value network.
### Detailed Analysis
* **Flow from Taskset:** The Taskset feeds into the Task Data Processor.
* A magnifying glass icon with a squiggly line is next to the Task Data Processor.
* The Task Data Processor outputs a "Task" to the Workflow Runner.
* **Workflow Runner Details:**
* The Agent interacts with the Environment, producing "action" and receiving "reward".
* The Agent also interacts with the Rollout Model and Reward Model.
* The Rollout Model outputs "Experience" to the Raw Experiences.
* **Experience Processing:**
* Raw Experiences are fed into the Experience Data Processor.
* A magnifying glass icon with a squiggly line is next to the Experience Data Processor.
* The Experience Data Processor outputs to Verified Experiences.
* **Trainer Details:**
* Verified Experiences are fed into the Reference Model, Actor Model, and Critic Model.
* The Reference Model feeds into the Actor Model.
* The Actor Model feeds into the Critic Model.
* "Sync. Weights" is written next to a gray arrow pointing from the Actor Model to the Agent.
* The Rollout Model outputs "Experience" to the Reference Model.
### Key Observations
* The diagram illustrates a closed-loop reinforcement learning system.
* The Workflow Runner is responsible for generating experiences.
* The Trainer is responsible for updating the models based on the experiences.
* The Buffer stores experiences for later use.
### Interpretation
The diagram depicts a typical reinforcement learning workflow, emphasizing the interaction between different components. The Taskset provides the initial tasks, which are then processed to generate experiences. These experiences are used to train the Actor and Critic models, which are then used by the Agent to interact with the Environment. The "Sync. Weights" arrow suggests that the Agent's policy is updated based on the Actor Model's weights, indicating a policy gradient approach. The presence of a Reference Model suggests a form of imitation learning or a stable learning target. The overall system aims to learn an optimal policy for the Agent to perform the given tasks within the Environment.