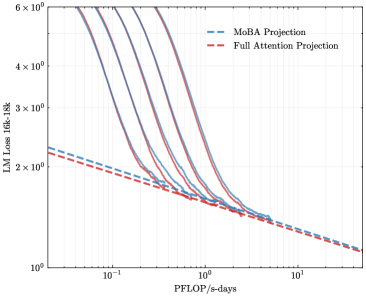
## Line Graph: LM Loss vs. PFLOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both lines depict the relationship between computational resources (PFLOP/s-days) and language model (LM) loss (measured in 16k-18k tokens). The graph uses logarithmic scales for both axes, with the y-axis ranging from 10⁰ to 6×10⁰ and the x-axis from 10⁻¹ to 10¹.
### Components/Axes
- **Y-Axis (Left)**: "LM Loss 16k-18k" (logarithmic scale, 10⁰ to 6×10⁰).
- **X-Axis (Bottom)**: "PFLOP/s-days" (logarithmic scale, 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner.
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~2.5×10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Decreases sharply to ~1.2×10⁰ at 10⁰ PFLOP/s-days.
- Continues declining to ~0.8×10⁰ at 10¹ PFLOP/s-days.
- Slope is steeper than the Full Attention Projection.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~2.2×10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Drops to ~1.0×10⁰ at 10⁰ PFLOP/s-days.
- Reaches ~0.6×10⁰ at 10¹ PFLOP/s-days.
- Slope is less steep than MoBA, indicating slower loss reduction.
3. **Convergence**:
- Both lines converge near 10¹ PFLOP/s-days, with MoBA Projection slightly above Full Attention Projection.
- At 10⁻¹ PFLOP/s-days, the gap between the two is ~0.3×10⁰.
### Key Observations
- **Efficiency Gap**: Full Attention Projection consistently achieves lower LM loss than MoBA Projection across all PFLOP/s-days values.
- **Diminishing Returns**: The rate of loss reduction slows as PFLOP/s-days increases, particularly for MoBA.
- **Logarithmic Scale Impact**: The logarithmic axes emphasize exponential improvements in efficiency, making early-stage gains (e.g., 10⁻¹ to 10⁰ PFLOP/s-days) appear more significant.
### Interpretation
The graph demonstrates that the Full Attention Projection is more computationally efficient than MoBA Projection, requiring fewer PFLOP/s-days to achieve the same LM loss reduction. The steeper slope of MoBA suggests it scales poorly with increased resources, while Full Attention maintains better performance even at higher computational costs. The convergence at 10¹ PFLOP/s-days implies that beyond this threshold, both methods plateau, but Full Attention remains superior. This highlights the importance of architectural efficiency in large-scale language models, where resource allocation directly impacts performance gains.