TECHNICAL ASSET FINGERPRINT
b2a19bc7df2f8d8648b88273
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
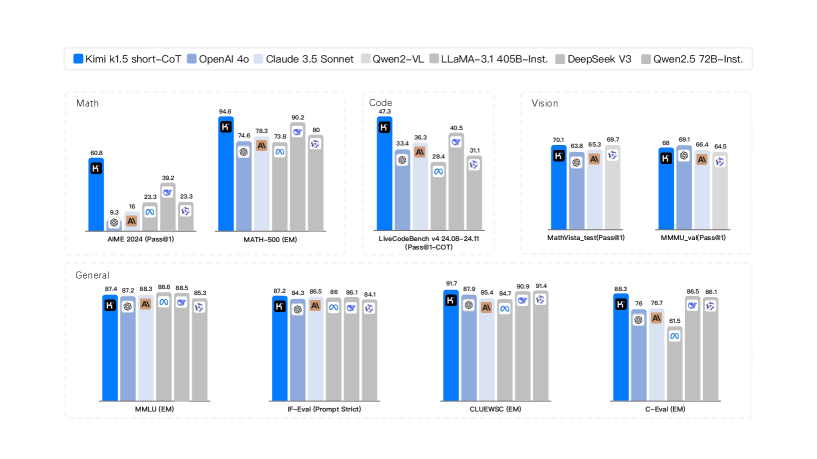
## Bar Chart Comparison: AI Model Performance Across Multiple Benchmarks
### Overview
The image is a composite bar chart comparing the performance of seven different large language models (LLMs) across eight distinct evaluation benchmarks. The benchmarks are grouped into four categories: Math, Code, Vision, and General. The chart uses a consistent color-coding scheme for each model, as defined in the legend at the top.
### Components/Axes
* **Legend (Top Center):** A horizontal legend identifies seven models with associated color codes:
* **Kimi k1.5 short-CoT:** Dark Blue
* **OpenAI 4o:** Light Blue
* **Claude 3.5 Sonnet:** Light Gray
* **Qwen2-VL:** Medium Gray
* **LLaMA-3.1 405B-Inst.:** Dark Gray
* **DeepSeek V3:** Very Light Gray
* **Qwen2.5 72B-Inst.:** Lightest Gray/White
* **Chart Structure:** The image is divided into four main rectangular panels, each containing one or two bar charts.
* **Top Left Panel (Math):** Contains two bar charts.
* **Top Center Panel (Code):** Contains one bar chart.
* **Top Right Panel (Vision):** Contains two bar charts.
* **Bottom Row (General):** Contains four bar charts.
* **Axes:** Each individual bar chart has:
* **Y-axis:** Represents the performance score (percentage or metric-specific value). The scale is not explicitly numbered, but values are annotated on top of each bar.
* **X-axis:** Lists the specific benchmark name for each group of bars.
### Detailed Analysis
#### **Math Category (Top Left Panel)**
1. **Benchmark: AIME 2024 (Pass@1)**
* **Kimi k1.5 short-CoT (Dark Blue):** 40.8
* **OpenAI 4o (Light Blue):** 9.3
* **Claude 3.5 Sonnet (Light Gray):** 16
* **Qwen2-VL (Medium Gray):** 23.3
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 39.2
* **DeepSeek V3 (Very Light Gray):** 33.3
* **Qwen2.5 72B-Inst. (Lightest Gray):** 33.3
* **Trend:** Kimi k1.5 and LLaMA-3.1 are the top performers, significantly ahead of others. OpenAI 4o has the lowest score.
2. **Benchmark: MATH-500 (EM)**
* **Kimi k1.5 short-CoT (Dark Blue):** 94.6
* **OpenAI 4o (Light Blue):** 74.6
* **Claude 3.5 Sonnet (Light Gray):** 78.3
* **Qwen2-VL (Medium Gray):** 73.8
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 86.2
* **DeepSeek V3 (Very Light Gray):** 80
* **Qwen2.5 72B-Inst. (Lightest Gray):** 80
* **Trend:** Kimi k1.5 shows a dominant lead. LLaMA-3.1 is second. The remaining models cluster in the 73-80 range.
#### **Code Category (Top Center Panel)**
1. **Benchmark: LiveCodeBench v4 24.08-24.11 (Pass@1-COT)**
* **Kimi k1.5 short-CoT (Dark Blue):** 47.9
* **OpenAI 4o (Light Blue):** 33.4
* **Claude 3.5 Sonnet (Light Gray):** 36.3
* **Qwen2-VL (Medium Gray):** 29.4
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 40.5
* **DeepSeek V3 (Very Light Gray):** 31.1
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible, appears to be the lowest)
* **Trend:** Kimi k1.5 leads, followed by LLaMA-3.1 and Claude 3.5 Sonnet. Qwen2-VL and DeepSeek V3 are at the lower end.
#### **Vision Category (Top Right Panel)**
1. **Benchmark: MathVista_test (Pass@1)**
* **Kimi k1.5 short-CoT (Dark Blue):** 70.1
* **OpenAI 4o (Light Blue):** 63.6
* **Claude 3.5 Sonnet (Light Gray):** 65.3
* **Qwen2-VL (Medium Gray):** 69.7
* **LLaMA-3.1 405B-Inst. (Dark Gray):** (Bar present but value not clearly visible)
* **DeepSeek V3 (Very Light Gray):** (Bar present but value not clearly visible)
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** Kimi k1.5 and Qwen2-VL are the top performers, very close in score. OpenAI 4o is the lowest among the clearly labeled scores.
2. **Benchmark: MMMU_val (Pass@1)**
* **Kimi k1.5 short-CoT (Dark Blue):** 68
* **OpenAI 4o (Light Blue):** 69.1
* **Claude 3.5 Sonnet (Light Gray):** 66.4
* **Qwen2-VL (Medium Gray):** 64.5
* **LLaMA-3.1 405B-Inst. (Dark Gray):** (Bar present but value not clearly visible)
* **DeepSeek V3 (Very Light Gray):** (Bar present but value not clearly visible)
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** OpenAI 4o has a slight lead over Kimi k1.5. Claude 3.5 Sonnet and Qwen2-VL follow closely.
#### **General Category (Bottom Row)**
1. **Benchmark: MMLU (EM)**
* **Kimi k1.5 short-CoT (Dark Blue):** 87.4
* **OpenAI 4o (Light Blue):** 87.2
* **Claude 3.5 Sonnet (Light Gray):** 88.3
* **Qwen2-VL (Medium Gray):** 88.6
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 88.5
* **DeepSeek V3 (Very Light Gray):** 88.3
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** Extremely tight clustering. Qwen2-VL has a marginal lead. All models score between approximately 87.2 and 88.6.
2. **Benchmark: IFEval (Prompt Strict)**
* **Kimi k1.5 short-CoT (Dark Blue):** 87.2
* **OpenAI 4o (Light Blue):** 84.3
* **Claude 3.5 Sonnet (Light Gray):** 86.5
* **Qwen2-VL (Medium Gray):** 86
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 86.1
* **DeepSeek V3 (Very Light Gray):** 84.1
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** Kimi k1.5 leads. Claude, Qwen2-VL, and LLaMA-3.1 are tightly grouped in the mid-86s. OpenAI 4o and DeepSeek V3 are slightly lower.
3. **Benchmark: CLUEWSC (EM)**
* **Kimi k1.5 short-CoT (Dark Blue):** 91.7
* **OpenAI 4o (Light Blue):** 87.9
* **Claude 3.5 Sonnet (Light Gray):** 85.4
* **Qwen2-VL (Medium Gray):** 86.7
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 90.8
* **DeepSeek V3 (Very Light Gray):** 91.4
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** Kimi k1.5 and DeepSeek V3 are the top performers, both above 91. LLaMA-3.1 is also strong at 90.8. Claude 3.5 Sonnet is the lowest.
4. **Benchmark: C-Eval (EM)**
* **Kimi k1.5 short-CoT (Dark Blue):** 88.2
* **OpenAI 4o (Light Blue):** 76
* **Claude 3.5 Sonnet (Light Gray):** 76.7
* **Qwen2-VL (Medium Gray):** 81.5
* **LLaMA-3.1 405B-Inst. (Dark Gray):** 86.5
* **DeepSeek V3 (Very Light Gray):** 86.1
* **Qwen2.5 72B-Inst. (Lightest Gray):** (Bar present but value not clearly visible)
* **Trend:** Kimi k1.5 has a clear lead. LLaMA-3.1 and DeepSeek V3 are strong seconds. OpenAI 4o and Claude 3.5 Sonnet are notably lower.
### Key Observations
1. **Model Dominance:** The **Kimi k1.5 short-CoT** model (dark blue bar) is the top performer in 6 out of the 8 benchmarks shown (AIME 2024, MATH-500, LiveCodeBench, MathVista_test, IFEval, CLUEWSC, C-Eval). It shows particular strength in mathematical and coding reasoning tasks.
2. **Competitive Tiers:** Performance is not uniform. In benchmarks like **MMLU**, all models are extremely competitive (within ~1.4 points). In others like **AIME 2024** or **MATH-500**, there is a significant performance gap between the leader and the rest.
3. **Vision Benchmark Split:** In the Vision category, the leadership changes. **Qwen2-VL** is very competitive with Kimi k1.5 on MathVista, and **OpenAI 4o** takes a slight lead on MMMU_val.
4. **Language-Specific Benchmark:** The **C-Eval** benchmark (likely Chinese-language focused) shows a different ranking, with Kimi k1.5 leading, followed by LLaMA-3.1 and DeepSeek V3, while OpenAI 4o and Claude 3.5 Sonnet score significantly lower.
5. **Data Gaps:** For several models (particularly Qwen2.5 72B-Inst., and some bars for LLaMA-3.1 and DeepSeek V3 in the Vision section), the exact numerical score is not clearly legible on the chart, though the bar height is visible.
### Interpretation
This chart provides a snapshot of the competitive landscape among leading LLMs as of the evaluation period (likely late 2024/early 2025 based on benchmark names). The data suggests that **Kimi k1.5 short-CoT** is a highly capable model, especially in tasks requiring complex reasoning (math, code, logic). Its consistent high performance across diverse domains indicates strong generalization.
The tight clustering in general knowledge benchmarks like **MMLU** suggests that top-tier models have reached a similar plateau of broad knowledge. Differentiation now occurs in specialized, harder tasks (e.g., competition-level math, live coding) and in specific domains like vision-language understanding or instruction following (**IFEval**).
The variation in rankings across benchmarks underscores that no single model is universally "best." The optimal choice depends on the specific application: **Qwen2-VL** for certain vision tasks, **OpenAI 4o** for MMMU, **DeepSeek V3** for CLUEWSC, etc. The strong showing of **LLaMA-3.1 405B-Inst.**, an open-weights model, across many benchmarks is notable, demonstrating that open models can compete closely with proprietary ones.
The chart effectively communicates that the field is highly competitive, with rapid iteration leading to frequent changes in the state-of-the-art across different evaluation axes.
DECODING INTELLIGENCE...