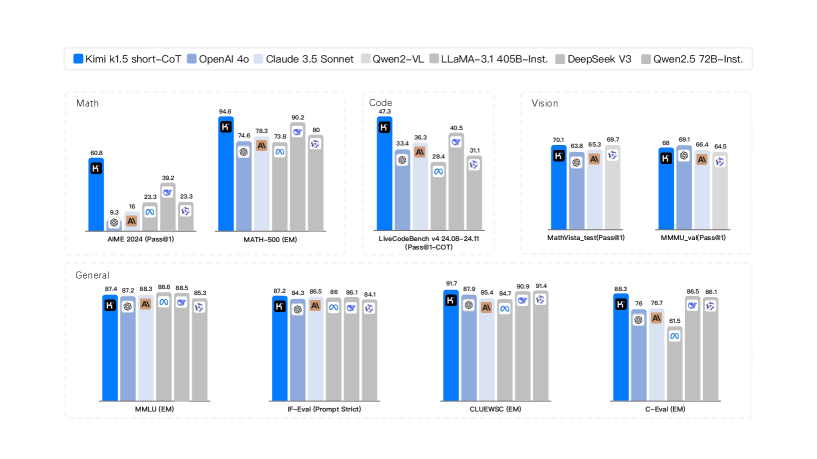
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
The image is a grouped bar chart comparing the performance of seven AI models across four task categories: Math, Code, Vision, and General. Each model is represented by a distinct color-coded bar, with numerical performance scores (in percentages) displayed atop each bar. The chart includes a legend at the top mapping colors to model names.
### Components/Axes
- **Legend**: Located at the top, mapping colors to models:
- Blue: Kimi 1.5 short-CoT
- Dark Blue: OpenAI 4o
- Light Blue: Claude 3.5 Sonnet
- Gray: Gwen2-VL
- Dark Gray: LLaMA-3.1 405B-Inst
- Brown: DeepSeek V3
- Light Brown: Gwen2.5 72B-Inst
- **X-Axis**: Task categories and benchmarks:
- Math: AIME 2024 (Pass@81), MATH-500 (EM)
- Code: LiveCodeBench v4 24.08-24.11 (Pass@1-CoT)
- Vision: MathVista_math (Pass@81), MMU_va (Pass@81)
- General: MMLU (EM), IF-Eval (Prompt Strict), CLUEWSC (EM), C-Eval (EM)
- **Y-Axis**: Performance scores (%), ranging from ~9% to ~94.6%.
### Detailed Analysis
#### Math
- **AIME 2024 (Pass@81)**:
- Kimi 1.5 short-CoT: 60.8%
- OpenAI 4o: 9.3%
- Claude 3.5 Sonnet: 16%
- Gwen2-VL: 23.3%
- LLaMA-3.1 405B-Inst: 22.3%
- DeepSeek V3: 16%
- Gwen2.5 72B-Inst: 23.3%
- **MATH-500 (EM)**:
- Kimi 1.5 short-CoT: 94.6%
- OpenAI 4o: 74.6%
- Claude 3.5 Sonnet: 79.5%
- Gwen2-VL: 80%
- LLaMA-3.1 405B-Inst: 73.8%
- DeepSeek V3: 80.2%
- Gwen2.5 72B-Inst: 80%
#### Code
- **LiveCodeBench v4 24.08-24.11 (Pass@1-CoT)**:
- Kimi 1.5 short-CoT: 42.3%
- OpenAI 4o: 36.3%
- Claude 3.5 Sonnet: 28.4%
- Gwen2-VL: 40.5%
- LLaMA-3.1 405B-Inst: 31.1%
- DeepSeek V3: 33.4%
- Gwen2.5 72B-Inst: 31.1%
#### Vision
- **MathVista_math (Pass@81)**:
- Kimi 1.5 short-CoT: 70.1%
- OpenAI 4o: 63.8%
- Claude 3.5 Sonnet: 65.3%
- Gwen2-VL: 69.7%
- LLaMA-3.1 405B-Inst: 63.8%
- DeepSeek V3: 65.3%
- Gwen2.5 72B-Inst: 69.7%
- **MMU_va (Pass@81)**:
- Kimi 1.5 short-CoT: 68%
- OpenAI 4o: 66.4%
- Claude 3.5 Sonnet: 64.5%
- Gwen2-VL: 69.1%
- LLaMA-3.1 405B-Inst: 66.4%
- DeepSeek V3: 64.5%
- Gwen2.5 72B-Inst: 69.1%
#### General
- **MMLU (EM)**:
- Kimi 1.5 short-CoT: 87.4%
- OpenAI 4o: 87.2%
- Claude 3.5 Sonnet: 88.6%
- Gwen2-VL: 85.5%
- LLaMA-3.1 405B-Inst: 85.3%
- DeepSeek V3: 88.6%
- Gwen2.5 72B-Inst: 85.3%
- **IF-Eval (Prompt Strict)**:
- Kimi 1.5 short-CoT: 87.2%
- OpenAI 4o: 84.3%
- Claude 3.5 Sonnet: 86.5%
- Gwen2-VL: 86%
- LLaMA-3.1 405B-Inst: 86.1%
- DeepSeek V3: 86.1%
- Gwen2.5 72B-Inst: 84.1%
- **CLUEWSC (EM)**:
- Kimi 1.5 short-CoT: 91.7%
- OpenAI 4o: 87.9%
- Claude 3.5 Sonnet: 85.4%
- Gwen2-VL: 84.7%
- LLaMA-3.1 405B-Inst: 85.4%
- DeepSeek V3: 90.9%
- Gwen2.5 72B-Inst: 91.4%
- **C-Eval (EM)**:
- Kimi 1.5 short-CoT: 83.3%
- OpenAI 4o: 70%
- Claude 3.5 Sonnet: 76.2%
- Gwen2-VL: 86.5%
- LLaMA-3.1 405B-Inst: 61.5%
- DeepSeek V3: 86.1%
- Gwen2.5 72B-Inst: 86.1%
### Key Observations
1. **Kimi 1.5 short-CoT** dominates in **Math (AIME 2024)** with 60.8% but underperforms in Code and General tasks compared to other models.
2. **LLaMA-3.1 405B-Inst** and **DeepSeek V3** show strong performance in Code (40.5% and 33.4%, respectively) and General tasks (90.9% and 88.6% for DeepSeek V3 in CLUEWSC).
3. **Gwen2-VL** and **Gwen2.5 72B-Inst** consistently score mid-to-high in Vision tasks but lag in Math and Code.
4. **OpenAI 4o** performs well in General tasks (87.2% in MMLU) but struggles in Math (9.3% in AIME 2024).
5. **Claude 3.5 Sonnet** has balanced performance across tasks, with no extreme outliers.
### Interpretation
The chart highlights **task-specific strengths** among AI models:
- **Kimi 1.5 short-CoT** excels in **Math (AIME 2024)** but lacks consistency in other domains.
- **LLaMA-3.1 405B-Inst** and **DeepSeek V3** demonstrate robustness in **Code and General tasks**, suggesting scalability with larger parameter counts.
- **Gwen2-VL** and **Gwen2.5 72B-Inst** specialize in **Vision tasks**, aligning with their architecture focused on visual reasoning.
- **OpenAI 4o** shows a trade-off between General and Math performance, indicating potential limitations in specialized reasoning.
The data underscores the importance of **model architecture and training focus** in determining task-specific efficacy. For example, Kimi’s high AIME score suggests advanced mathematical reasoning capabilities, while LLaMA’s performance in Code reflects its general-purpose design. However, no single model dominates all tasks, emphasizing the need for task-aware model selection.