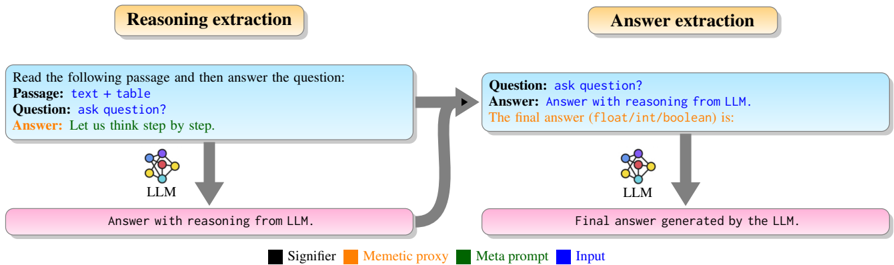
## Diagram: Reasoning and Answer Extraction using LLM
### Overview
The image is a diagram illustrating the process of reasoning and answer extraction using a Large Language Model (LLM). It shows a two-stage process: Reasoning extraction and Answer extraction. The diagram uses color-coded boxes and arrows to represent the flow of information and the involvement of the LLM. A legend at the bottom explains the color codes.
### Components/Axes
* **Titles:** "Reasoning extraction" (top-left), "Answer extraction" (top-right)
* **Input Boxes (Blue):**
* Left: "Read the following passage and then answer the question:\nPassage: text + table\nQuestion: ask question?\nAnswer: Let us think step by step."
* Right: "Question: ask question?\nAnswer: Answer with reasoning from LLM.\nThe final answer (float/int/boolean) is:"
* **LLM Icons:** Represented by a multi-colored node diagram, positioned below each input box.
* **Output Boxes (Pink):**
* Left: "Answer with reasoning from LLM."
* Right: "Final answer generated by the LLM."
* **Arrows:** Indicate the flow of information. A gray arrow connects the output of the "Reasoning extraction" stage to the input of the "Answer extraction" stage.
* **Legend (Bottom):**
* Black square: "Signifier"
* Orange square: "Memetic proxy"
* Green square: "Meta prompt"
* Blue square: "Input"
### Detailed Analysis or ### Content Details
1. **Reasoning Extraction:**
* The process begins with an input box containing a passage (text + table), a question ("ask question?"), and an initial answer ("Let us think step by step.").
* This input is fed into an LLM.
* The output is "Answer with reasoning from LLM."
2. **Answer Extraction:**
* The output from the reasoning extraction stage, along with a new question ("ask question?") and a prompt for the final answer type ("The final answer (float/int/boolean) is:"), serves as input to the second stage.
* This input is processed by another LLM.
* The final output is "Final answer generated by the LLM."
3. **Color Coding:**
* The input boxes are blue.
* The output boxes are pink.
* The titles "Reasoning extraction" and "Answer extraction" are in boxes with an orange background.
* The LLM is represented by a multi-colored node diagram.
### Key Observations
* The diagram illustrates a two-step process for answering questions using an LLM.
* The first step focuses on reasoning, while the second step focuses on generating the final answer.
* The diagram highlights the importance of providing the LLM with both the question and relevant context (passage, initial answer).
### Interpretation
The diagram demonstrates a structured approach to leveraging LLMs for question answering. By separating the reasoning and answer generation stages, the process aims to improve the accuracy and reliability of the final answer. The use of specific prompts, such as specifying the expected data type of the answer (float/int/boolean), further refines the LLM's output. The diagram suggests that a well-designed input, combined with a multi-stage processing approach, can enhance the performance of LLMs in complex tasks.