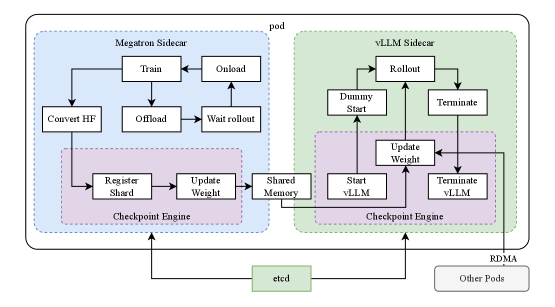
## Diagram: Distributed Machine Learning Workflow Architecture
### Overview
The diagram illustrates a distributed machine learning workflow architecture with two primary components: **Megatron Sidecar** (blue) and **vLLM Sidecar** (green), connected via a **Checkpoint Engine** (purple). Processes flow between these components, with infrastructure elements like **etcd** (green) and **RDMA** (gray) at the bottom. Arrows indicate directional relationships between steps.
### Components/Axes
#### Key Labels and Elements:
1. **Megatron Sidecar (Blue)**:
- `Convert HF` → `Train` → `Onload`
- `Offload` → `Wait rollout`
- `Register Shard` → `Update Weight`
- `Checkpoint Engine` (central hub for shard/weight management).
2. **vLLM Sidecar (Green)**:
- `Rollout` → `Dummy Start`
- `Update Weight` → `Start vLLM` → `Terminate vLLM`
- Feedback loop: `Terminate vLLM` → `Update Weight`.
3. **Checkpoint Engine (Purple)**:
- Connects `Register Shard` (Megatron) and `Update Weight` (vLLM).
- Shares `Shared Memory` with vLLM Sidecar.
4. **Infrastructure**:
- `etcd` (green): Centralized key-value store for coordination.
- `RDMA` (gray): High-speed network interface.
- `Other Pods`: External components interacting via RDMA.
#### Flow Direction:
- **Megatron → Checkpoint Engine**: `Register Shard` and `Update Weight` propagate to the Checkpoint Engine.
- **Checkpoint Engine → vLLM**: `Update Weight` and `Shared Memory` are shared with the vLLM Sidecar.
- **vLLM → Checkpoint Engine**: `Update Weight` feedback loop from `Terminate vLLM`.
### Detailed Analysis
- **Megatron Sidecar**:
- `Convert HF`: Converts Hugging Face models for training.
- `Train` → `Onload`: Training process followed by data loading.
- `Offload` → `Wait rollout`: Model weights offloaded to disk, awaiting rollout completion.
- `Register Shard`: Shard registration for distributed training.
- `Update Weight`: Weight updates synchronized via the Checkpoint Engine.
- **vLLM Sidecar**:
- `Rollout`: Model deployment for inference.
- `Dummy Start`: Placeholder for model initialization.
- `Update Weight`: Weight updates from Megatron or feedback loops.
- `Start vLLM` → `Terminate vLLM`: Lifecycle management of inference instances.
- **Checkpoint Engine**:
- Acts as a central coordinator for shard/weight synchronization.
- `Shared Memory`: Enables low-latency communication between sidecars.
- **Infrastructure**:
- `etcd`: Likely manages distributed state (e.g., pod status, configuration).
- `RDMA`: Facilitates high-throughput, low-latency data transfer between pods.
### Key Observations
1. **Feedback Loops**:
- `Terminate vLLM` → `Update Weight` suggests iterative model refinement.
- `Wait rollout` → `Offload` indicates staged model deployment.
2. **Component Coupling**:
- The Checkpoint Engine bridges Megatron (training) and vLLM (inference), enabling real-time weight updates.
- `Shared Memory` reduces latency in cross-sidecar communication.
3. **Infrastructure Role**:
- `etcd` and `RDMA` support scalability and performance in distributed environments.
### Interpretation
This architecture represents a **model-as-a-service (MaaS)** system where:
- **Megatron Sidecar** handles training and weight management.
- **vLLM Sidecar** manages inference rollouts and lifecycle.
- The **Checkpoint Engine** ensures consistency between training and inference by synchronizing weights and shards.
- **RDMA** and **etcd** optimize performance and coordination in a distributed setup.
The diagram emphasizes **modularity** (separate training/inference pipelines) and **efficiency** (low-latency updates via shared memory and RDMA). The feedback loops suggest a dynamic system where inference results may inform training adjustments.