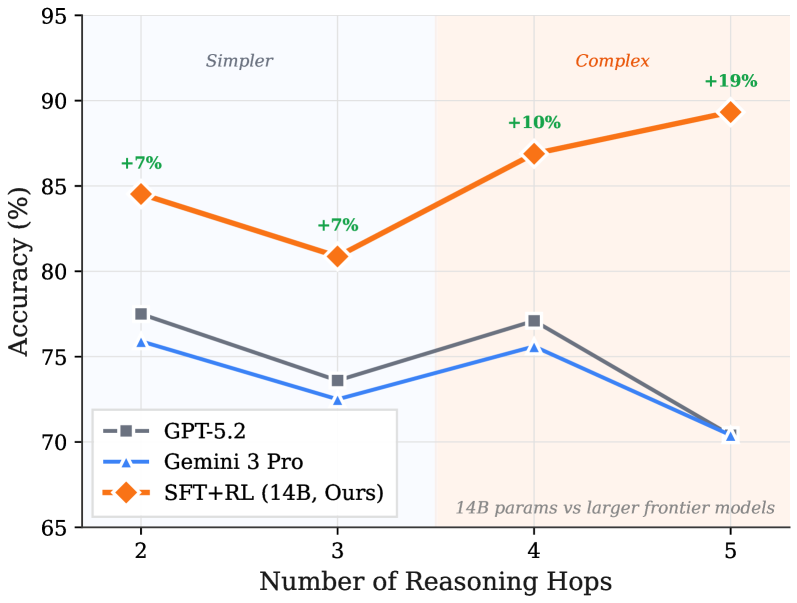
## Line Chart: Accuracy vs. Reasoning Hops for Language Models
### Overview
This line chart compares the accuracy of three language models – GPT-5.2, Gemini 3 Pro, and SFT+RL (14B, Ours) – as the number of reasoning hops increases. The chart highlights a performance difference between a smaller model (SFT+RL) and larger frontier models (GPT-5.2 and Gemini 3 Pro) as the complexity of the reasoning task increases. The x-axis represents the number of reasoning hops, and the y-axis represents the accuracy in percentage. The chart is divided into two regions labeled "Simpler" and "Complex" based on the number of reasoning hops.
### Components/Axes
* **X-axis:** Number of Reasoning Hops (Scale: 2, 3, 4, 5)
* **Y-axis:** Accuracy (%) (Scale: 65, 70, 75, 80, 85, 90, 95)
* **Legend:**
* GPT-5.2 (Grey dashed line)
* Gemini 3 Pro (Blue dashed line)
* SFT+RL (14B, Ours) (Orange solid line)
* **Regions:**
* "Simpler" (Reasoning Hops 2 & 3) - Light orange background
* "Complex" (Reasoning Hops 4 & 5) - Light green background
* **Annotation:** "14B params vs larger frontier models" (Bottom-right corner)
* **Percentage Change Annotations:** "+7%", "+7%", "+10%", "+19%" (placed near the SFT+RL data points)
### Detailed Analysis
* **GPT-5.2 (Grey dashed line):** The line starts at approximately 76% accuracy at 2 reasoning hops, decreases slightly to around 74% at 3 hops, increases to approximately 76% at 4 hops, and then drops sharply to around 70% at 5 hops.
* **Gemini 3 Pro (Blue dashed line):** The line begins at approximately 73% accuracy at 2 reasoning hops, decreases to around 72% at 3 hops, remains relatively stable at approximately 73% at 4 hops, and then declines to around 69% at 5 hops.
* **SFT+RL (14B, Ours) (Orange solid line):** The line starts at approximately 84% accuracy at 2 reasoning hops, decreases to around 81% at 3 hops, increases significantly to approximately 87% at 4 hops, and continues to increase to approximately 91% at 5 hops. The percentage changes are annotated as +7% (from 2 to 3 hops), +7% (from 3 to 4 hops), +10% (from 4 to 5 hops), and +19% (overall from 2 to 5 hops).
### Key Observations
* SFT+RL (14B) consistently outperforms GPT-5.2 and Gemini 3 Pro across all reasoning hop levels.
* The performance gap between SFT+RL and the other models widens as the number of reasoning hops increases, particularly in the "Complex" region (4 and 5 hops).
* GPT-5.2 and Gemini 3 Pro exhibit a decreasing trend in accuracy as the number of reasoning hops increases, suggesting they struggle with more complex reasoning tasks.
* SFT+RL demonstrates an increasing trend in accuracy with more reasoning hops, indicating its ability to handle more complex tasks effectively.
### Interpretation
The data suggests that the SFT+RL (14B) model, despite being smaller in parameter size compared to GPT-5.2 and Gemini 3 Pro, is more robust and effective at handling complex reasoning tasks. The increasing accuracy of SFT+RL with more reasoning hops indicates that it benefits from deeper reasoning chains, while the larger models appear to be hindered by increased complexity. This could be due to differences in training data, model architecture, or optimization techniques. The annotation "14B params vs larger frontier models" explicitly highlights this comparison. The division into "Simpler" and "Complex" regions suggests a transition point where the benefits of the SFT+RL model become more pronounced. The consistent decline in performance for the larger models as reasoning hops increase could indicate issues with error propagation or difficulty maintaining coherence over longer reasoning chains. The +19% overall improvement for SFT+RL is a significant finding, demonstrating its potential as a competitive alternative to larger language models for reasoning-intensive tasks.