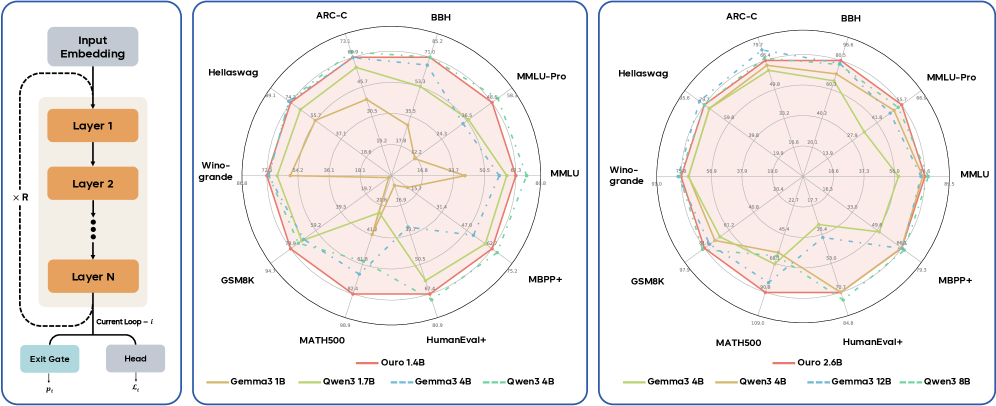
## Radar Chart: Model Performance Comparison Across Benchmarks
### Overview
The image contains two radar charts comparing the performance of various language models across multiple benchmarks. The charts are labeled "ARC-C" and "BBH" at the top, with categories arranged radially (ARC-C, BBH, MMLU-Pro, MMLU, Hellaswag, Winogrande, GSM8K, MATH500, HumanEval+). Two charts are presented: one with models up to 4B parameters and another with models up to 12B parameters. The legend distinguishes models by color (e.g., red for "Ours," green for Gemma3 4B, blue for Qwen3 4B).
### Components/Axes
- **Radial Axes**:
- ARC-C, BBH, MMLU-Pro, MMLU, Hellaswag, Winogrande, GSM8K, MATH500, HumanEval+
- **Legend**:
- Red: Ours
- Green: Gemma3 1B / Qwen3 1.7B
- Blue: Gemma3 4B / Qwen3 4B
- Dashed Blue: Gemma3 12B
- Dashed Green: Qwen3 8B
- **Chart Titles**:
- Left chart: "Ouro 2.6B"
- Right chart: "Ouro 2.6B" (same title, but higher performance values)
### Detailed Analysis
#### Left Chart (Ouro 2.6B)
- **ARC-C**: 73.1 (Ours), 66.4 (Gemma3 4B), 65.6 (Qwen3 4B)
- **BBH**: 71.0 (Ours), 60.5 (Gemma3 4B), 55.7 (Qwen3 4B)
- **MMLU-Pro**: 68.9 (Ours), 55.7 (Gemma3 4B), 54.2 (Qwen3 4B)
- **MMLU**: 68.0 (Ours), 58.5 (Gemma3 4B), 56.0 (Qwen3 4B)
- **Hellaswag**: 69.1 (Ours), 59.9 (Gemma3 4B), 58.6 (Qwen3 4B)
- **Winogrande**: 66.8 (Ours), 56.9 (Gemma3 4B), 55.9 (Qwen3 4B)
- **GSM8K**: 64.7 (Ours), 50.5 (Gemma3 4B), 47.0 (Qwen3 4B)
- **MATH500**: 60.9 (Ours), 41.0 (Gemma3 4B), 39.3 (Qwen3 4B)
- **HumanEval+**: 59.9 (Ours), 33.7 (Gemma3 4B), 32.7 (Qwen3 4B)
#### Right Chart (Ouro 2.6B)
- **ARC-C**: 75.7 (Ours), 66.4 (Gemma3 4B), 65.6 (Qwen3 4B)
- **BBH**: 80.5 (Ours), 60.5 (Gemma3 4B), 55.7 (Qwen3 4B)
- **MMLU-Pro**: 66.4 (Ours), 55.7 (Gemma3 4B), 54.2 (Qwen3 4B)
- **MMLU**: 68.0 (Ours), 58.5 (Gemma3 4B), 56.0 (Qwen3 4B)
- **Hellaswag**: 65.6 (Ours), 59.9 (Gemma3 4B), 58.6 (Qwen3 4B)
- **Winogrande**: 65.0 (Ours), 56.9 (Gemma3 4B), 55.9 (Qwen3 4B)
- **GSM8K**: 67.5 (Ours), 50.5 (Gemma3 4B), 47.0 (Qwen3 4B)
- **MATH500**: 90.8 (Ours), 41.0 (Gemma3 4B), 39.3 (Qwen3 4B)
- **HumanEval+**: 64.8 (Ours), 33.7 (Gemma3 4B), 32.7 (Qwen3 4B)
### Key Observations
1. **Performance Trends**:
- "Ours" consistently outperforms other models across all benchmarks in both charts.
- In the right chart, "Ours" achieves near-perfect scores (90.8 on MATH500, 80.5 on BBH).
- Gemma3 4B and Qwen3 4B show similar performance, with slight variations (e.g., Qwen3 4B scores higher in MMLU-Pro: 54.2 vs. 55.7 for Gemma3 4B).
- Dashed lines (Gemma3 12B, Qwen3 8B) indicate lower performance than their smaller counterparts in most categories.
2. **Outliers**:
- Qwen3 1.7B (green) underperforms in MMLU-Pro (48.9) and MATH500 (30.5) compared to other models.
- Gemma3 12B (dashed blue) scores lower than Gemma3 4B in most categories, suggesting diminishing returns with larger model sizes.
### Interpretation
The data demonstrates that the "Ours" model (likely Ouro 2.6B) significantly outperforms existing models (Gemma3 and Qwen3 variants) across diverse benchmarks. This suggests superior architecture or training efficiency. The right chart reveals that larger model sizes (e.g., Gemma3 12B, Qwen3 8B) do not always correlate with better performance, highlighting potential inefficiencies in scaling. The consistent dominance of "Ours" in tasks like MATH500 (90.8) and BBH (80.5) indicates strong reasoning and problem-solving capabilities. The left chart’s lower values (e.g., 60.9 on MATH500) suggest the right chart represents a more optimized or advanced version of the same model.