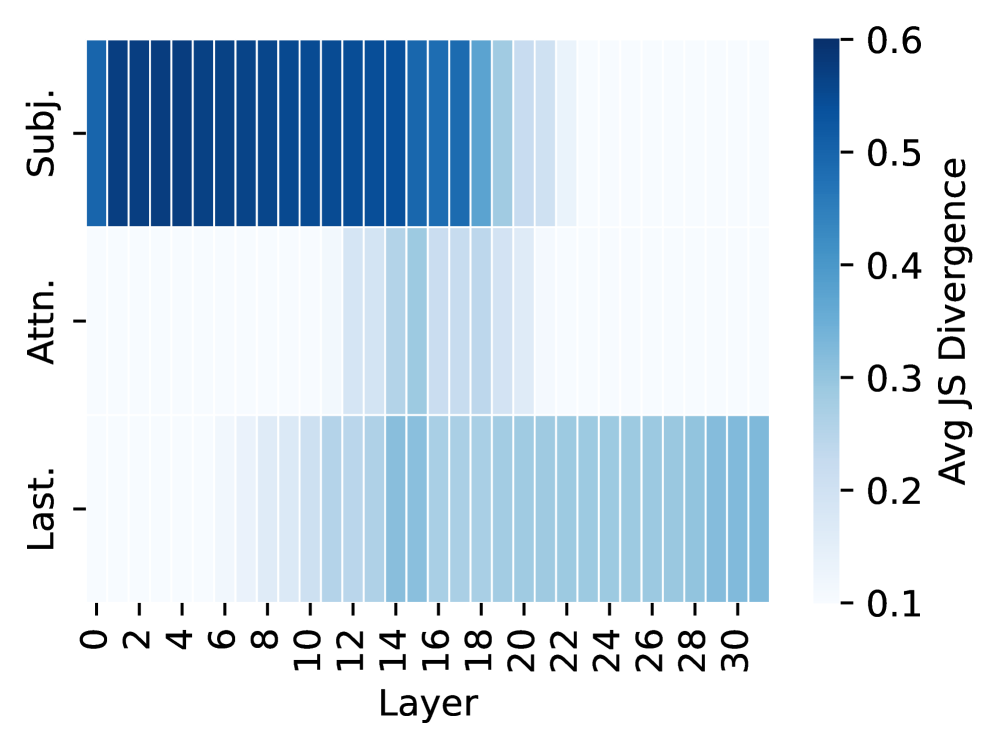
## Heatmap: Avg JS Divergence Across Layers
### Overview
The image is a heatmap visualizing the average Jensen-Shannon (JS) divergence across different layers for three categories: Subj. (Subject), Attn. (Attention), and Last. The x-axis represents the layer number, ranging from 0 to 30. The y-axis represents the three categories. The color intensity represents the magnitude of the average JS divergence, with darker blue indicating higher divergence and lighter blue indicating lower divergence.
### Components/Axes
* **X-axis:** Layer (numerical, ranges from 0 to 30 in increments of 2)
* **Y-axis:** Categories (Subj., Attn., Last.)
* **Color Scale (Legend):** Avg JS Divergence (ranges from 0.1 to 0.6, with darker blue representing higher values and lighter blue representing lower values). The scale has tick marks at 0.1, 0.2, 0.3, 0.4, 0.5, and 0.6.
### Detailed Analysis
* **Subj. (Subject):** The JS divergence is high (dark blue) for layers 0 to approximately 18. From layer 20 onwards, the JS divergence decreases (lighter blue). The approximate value for layers 0-18 is around 0.5-0.6. The approximate value for layers 20-30 is around 0.4-0.5.
* **Attn. (Attention):** The JS divergence starts low (light blue) and gradually increases (darker blue) as the layer number increases. The approximate value for layers 0-10 is around 0.1-0.2. The approximate value for layers 20-30 is around 0.3-0.4.
* **Last.:** The JS divergence is relatively low (light blue) across all layers. The approximate value is around 0.2-0.3.
### Key Observations
* The "Subj." category has the highest JS divergence in the initial layers, which decreases as the layer number increases.
* The "Attn." category has the lowest JS divergence in the initial layers, which increases as the layer number increases.
* The "Last." category has a consistently low JS divergence across all layers.
### Interpretation
The heatmap suggests that the "Subject" information is most divergent in the earlier layers of the model, while "Attention" becomes more divergent in the later layers. The "Last" category shows consistently low divergence across all layers, which might indicate that it represents a more stable or less variable aspect of the data. The JS divergence can be interpreted as a measure of how different the probability distributions are between different layers for each category. Higher divergence suggests greater differences in the information being processed at those layers.