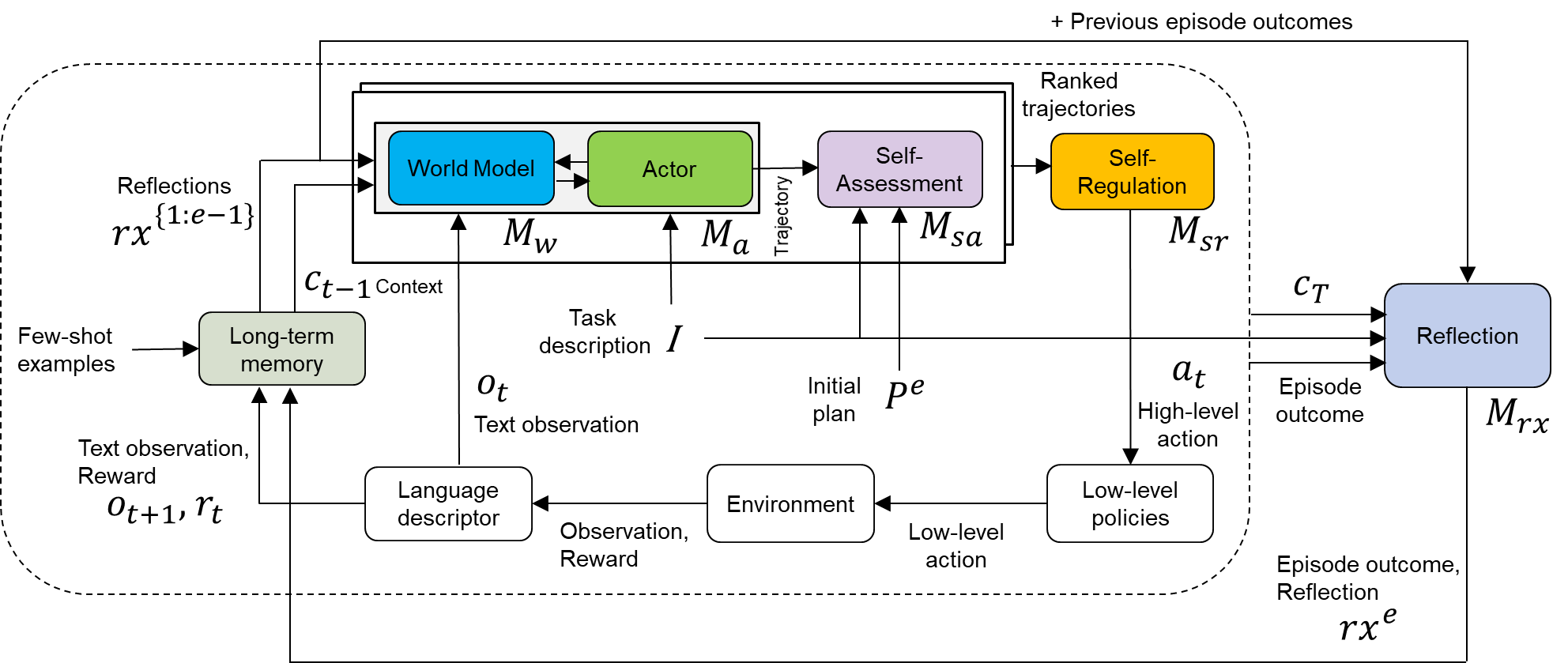
## Diagram: High-Level System Architecture
### Overview
The image presents a high-level system architecture diagram, likely for a reinforcement learning or AI system. It illustrates the flow of information and interactions between various components, including a world model, actor, self-assessment, self-regulation, long-term memory, language descriptor, environment, and reflection mechanism. The diagram emphasizes the iterative nature of the process, with feedback loops and context-dependent decision-making.
### Components/Axes
* **Nodes (Rounded Rectangles):** Represent distinct modules or components within the system.
* World Model (Blue)
* Actor (Green)
* Self-Assessment (Purple)
* Self-Regulation (Yellow)
* Long-term memory (Light Green)
* Language descriptor (White)
* Environment (White)
* Low-level policies (White)
* Reflection (Light Blue)
* **Arrows:** Indicate the flow of information or control between components.
* **Labels:** Describe the data or signals being passed between components.
* Reflections rx{1:e-1}
* Ct-1 Context
* Task description I
* Ot Text observation
* Initial plan Pe
* At High-level action
* Episode outcome
* Text observation, Reward Ot+1, rt
* Observation, Reward
* Low-level action
* Episode outcome, Reflection rxe
* Ranked trajectories
* \+ Previous episode outcomes
* **Variables:**
* Mw
* Ma
* Msa
* Msr
* Mrx
### Detailed Analysis or ### Content Details
1. **Central Processing Unit:**
* A dashed rounded rectangle encloses the "World Model," "Actor," "Self-Assessment," and "Self-Regulation" modules. This grouping suggests a central processing unit or core decision-making component.
* The "World Model" (blue) receives input from "Reflections rx{1:e-1}" and "Ct-1 Context". It outputs to the "Actor".
* The "Actor" (green) receives input from the "World Model" and "Task description I". It outputs a "Trajectory" to the "Self-Assessment" module.
* The "Self-Assessment" (purple) receives the "Trajectory" and "Initial plan Pe". It outputs to the "Self-Regulation" module.
* The "Self-Regulation" (yellow) receives input from "Self-Assessment" and outputs "At High-level action" and "Ranked trajectories".
2. **Memory and Context:**
* "Long-term memory" (light green) receives "Few-shot examples" and "Text observation, Reward Ot+1, rt". It outputs "Ct-1 Context" to the "World Model".
3. **Environment Interaction:**
* "Language descriptor" (white) receives "Observation, Reward" from the "Environment" (white) and outputs "Text observation, Reward Ot+1, rt" to the "Long-term memory". It also outputs "Ot Text observation" to the "World Model".
* The "Environment" receives "Low-level action" from "Low-level policies" (white) and outputs "Observation, Reward" to the "Language descriptor".
* "Low-level policies" receives "At High-level action" from "Self-Regulation" and outputs "Low-level action" to the "Environment".
4. **Reflection Mechanism:**
* The "Reflection" module (light blue) receives "Ranked trajectories" (indirectly from "Self-Regulation"), "Ct", and "Episode outcome". It outputs "Reflections rx{1:e-1}" to the "World Model" and "Episode outcome, Reflection rxe" to the "Long-term memory".
* The "Reflection" module also receives "+ Previous episode outcomes" as input.
### Key Observations
* The system incorporates a hierarchical structure, with high-level planning and decision-making ("World Model," "Actor," "Self-Assessment," "Self-Regulation") interacting with lower-level policies and the environment.
* Feedback loops are prevalent, allowing the system to learn from its experiences and adapt its behavior.
* The "Reflection" module plays a crucial role in learning and knowledge accumulation.
* The system integrates both textual and reward-based information.
### Interpretation
The diagram illustrates a sophisticated AI system designed for complex tasks. The system leverages a world model to reason about the environment, an actor to take actions, and self-assessment and self-regulation mechanisms to improve performance. The inclusion of long-term memory and a reflection module suggests a system capable of continuous learning and adaptation. The system appears to be designed to learn from both successful and unsuccessful episodes, using the reflection mechanism to extract valuable insights. The integration of language and reward signals indicates a system that can understand and respond to both human instructions and environmental feedback. The overall architecture suggests a system capable of handling complex, dynamic environments and learning to achieve long-term goals.