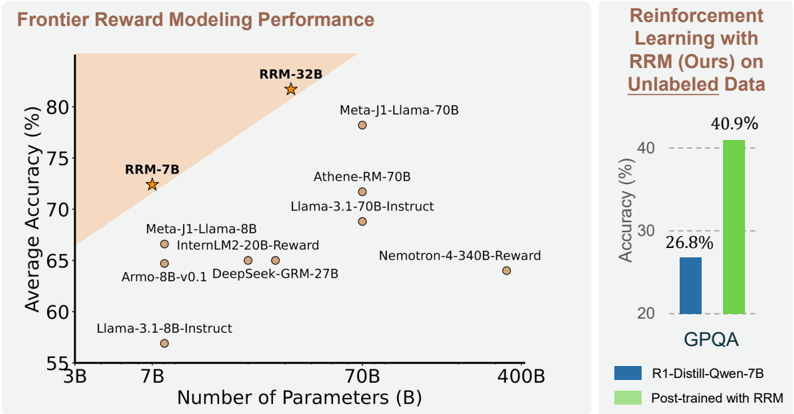
## Scatter Plot: Frontier Reward Modeling Performance
### Overview
The image presents a scatter plot comparing model performance (average accuracy %) against model size (number of parameters in billions). A secondary bar chart on the right compares accuracy metrics before and after reinforcement learning with RRM (Reinforcement Reward Modeling). The plot includes 10 labeled data points and a shaded "frontier" region.
### Components/Axes
**Main Chart:**
- **X-axis**: Number of Parameters (B) - Logarithmic scale from 3B to 400B
- **Y-axis**: Average Accuracy (%) - Linear scale from 55% to 80%
- **Legend**:
- Blue: "R1-Distill-Qwen-7B" (baseline)
- Green: "Post-trained with RRM" (enhanced)
- **Shaded Region**: Light orange triangle labeled "Frontier Reward Modeling Performance" in top-left quadrant
**Bar Chart (Right Panel):**
- **Title**: "Reinforcement Learning with RRM (Ours) on Unlabeled Data"
- **X-axis**: Two categories:
- "R1-Distill-Qwen-7B" (blue)
- "Post-trained with RRM" (green)
- **Y-axis**: Accuracy (%) - Linear scale from 20% to 40%
### Detailed Analysis
**Main Chart Data Points:**
1. **RRM-32B** (Star symbol): 80% accuracy at 32B parameters (top-right of shaded region)
2. **RRM-7B** (Star symbol): 72% accuracy at 7B parameters (left edge of shaded region)
3. **Meta-J1-Llama-70B**: 78% accuracy at 70B parameters
4. **Athene-RM-70B**: 70% accuracy at 70B parameters
5. **Llama-3.1-70B-Instruct**: 68% accuracy at 70B parameters
6. **Meta-J1-Llama-8B**: 65% accuracy at 8B parameters
7. **InternLM2-20B-Reward**: 65% accuracy at 20B parameters
8. **DeepSeek-GRM-27B**: 65% accuracy at 27B parameters
9. **Armo-8B-v0.1**: 63% accuracy at 8B parameters
10. **Llama-3.1-8B-Instruct**: 58% accuracy at 8B parameters
**Bar Chart Values:**
- Baseline (R1-Distill-Qwen-7B): 26.8% accuracy
- Post-trained with RRM: 40.9% accuracy
### Key Observations
1. **Frontier Region**: The shaded orange triangle contains the highest-performing models (RRM-32B and RRM-7B), suggesting this region represents optimal parameter-accuracy tradeoffs.
2. **Parameter Efficiency**: RRM-7B (7B parameters) achieves 72% accuracy, outperforming larger models like Llama-3.1-70B-Instruct (68% at 70B parameters).
3. **RRM Impact**: The bar chart shows a 14.1% absolute improvement (26.8% → 40.9%) when using RRM post-training.
4. **Model Clustering**: Models with 70B parameters cluster between 68-78% accuracy, while smaller models (8B) range from 58-65%.
### Interpretation
The data demonstrates that:
1. **RRM Enhances Performance**: Post-training with RRM significantly improves accuracy across all model sizes, with the most dramatic gains in smaller models (e.g., 8B → 65% vs 58%).
2. **Efficiency Frontier**: The shaded region identifies models achieving high accuracy with relatively few parameters, suggesting RRM enables better sample efficiency.
3. **Scaling Law**: While larger models generally perform better, the frontier models (RRM-7B/32B) break this trend by achieving competitive accuracy with fewer parameters.
4. **Instruction Tuning Tradeoff**: Llama-3.1-8B-Instruct (58%) underperforms its reward-trained counterpart (Meta-J1-Llama-8B at 65%), indicating instruction tuning alone may not suffice for optimal performance.
The visualization suggests RRM provides a dual benefit: improving accuracy while maintaining parameter efficiency, making it particularly valuable for deployment in resource-constrained environments.