TECHNICAL ASSET FINGERPRINT
b71699ebf98f12824f2c30c1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
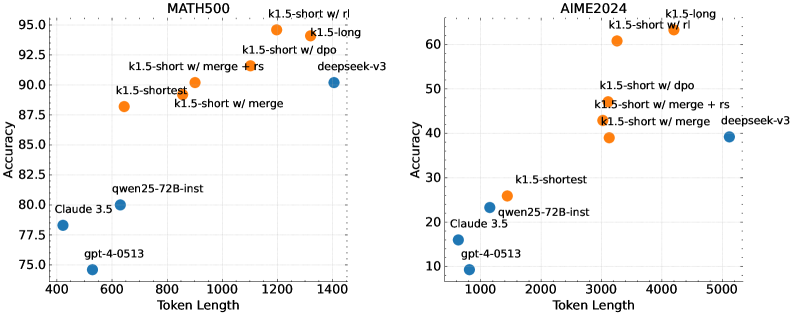
## Scatter Plot Comparison: MATH500 vs. AIME2024 Benchmark Performance
### Overview
The image displays two side-by-side scatter plots comparing the performance of various large language models on two different mathematical reasoning benchmarks: **MATH500** (left) and **AIME2024** (right). Each plot charts model **Accuracy** (y-axis) against **Token Length** (x-axis), which likely represents the model's context window or sequence length. Data points are color-coded, with orange representing variants of a model family labeled "k1.5" and blue representing other models (e.g., deepseek-v3, Claude 3.5, gpt-4-0513, qwen25-72B-inst).
### Components/Axes
**Common Elements:**
* **X-axis:** "Token Length" (linear scale).
* **Y-axis:** "Accuracy" (linear scale, percentage).
* **Data Points:** Labeled circles. Orange points are various "k1.5" model configurations. Blue points are comparison models.
* **Titles:** Centered above each plot.
**Left Plot: MATH500**
* **Title:** "MATH500"
* **X-axis Range:** ~400 to ~1400
* **Y-axis Range:** 75.0 to 95.0
* **Data Points & Approximate Coordinates (Token Length, Accuracy):**
* **Orange (k1.5 family):**
* `k1.5-shortest`: (~650, ~88.5)
* `k1.5-short w/ merge`: (~900, ~89.0)
* `k1.5-short w/ merge + rs`: (~1100, ~91.5)
* `k1.5-short w/ dpo`: (~1200, ~93.0)
* `k1.5-short w/ rl`: (~1200, ~95.0) *[Highest point]*
* `k1.5-long`: (~1350, ~94.0)
* **Blue (Other models):**
* `gpt-4-0513`: (~550, ~75.0) *[Lowest point]*
* `Claude 3.5`: (~450, ~78.5)
* `qwen25-72B-inst`: (~650, ~80.0)
* `deepseek-v3`: (~1400, ~90.0)
**Right Plot: AIME2024**
* **Title:** "AIME2024"
* **X-axis Range:** ~1000 to ~5000
* **Y-axis Range:** 10 to 60
* **Data Points & Approximate Coordinates (Token Length, Accuracy):**
* **Orange (k1.5 family):**
* `k1.5-shortest`: (~1500, ~26.0)
* `k1.5-short w/ merge`: (~3000, ~39.0)
* `k1.5-short w/ merge + rs`: (~3200, ~43.0)
* `k1.5-short w/ dpo`: (~3200, ~46.0)
* `k1.5-short w/ rl`: (~3300, ~61.0) *[Highest point]*
* `k1.5-long`: (~4200, ~63.0) *[Highest point, slightly above rl variant]*
* **Blue (Other models):**
* `gpt-4-0513`: (~1000, ~9.0) *[Lowest point]*
* `Claude 3.5`: (~900, ~16.0)
* `qwen25-72B-inst`: (~1200, ~21.0)
* `deepseek-v3`: (~5100, ~39.0)
### Detailed Analysis
**MATH500 Plot Analysis:**
* **Trend Verification:** There is a clear positive correlation between Token Length and Accuracy for the k1.5 model family (orange points). The line formed by these points slopes upward from left to right. The blue comparison models do not follow a single clear trend relative to token length.
* **Performance Hierarchy:** The `k1.5-short w/ rl` model achieves the highest accuracy (~95%). The `k1.5-long` model is close behind (~94%). The standard `gpt-4-0513` model shows the lowest accuracy (~75%) among the plotted points.
* **Token Length Clustering:** The k1.5 models cluster in the higher token length range (650-1400), while the comparison models (except `deepseek-v3`) are in the lower range (450-650).
**AIME2024 Plot Analysis:**
* **Trend Verification:** A positive correlation is also visible for the k1.5 family, with accuracy generally increasing with token length. The slope appears steeper than in the MATH500 plot. The `deepseek-v3` point is an outlier in terms of token length (~5100) but has moderate accuracy (~39%).
* **Performance Hierarchy:** The `k1.5-long` model achieves the highest accuracy (~63%), narrowly outperforming the `k1.5-short w/ rl` variant (~61%). The `gpt-4-0513` model again shows the lowest accuracy (~9%).
* **Scale Difference:** The overall accuracy values are significantly lower on AIME2024 (max ~63%) compared to MATH500 (max ~95%), indicating this is a more challenging benchmark. Token lengths are also generally higher.
### Key Observations
1. **Consistent Leader:** The `k1.5-short w/ rl` (reinforcement learning) variant is a top performer on both benchmarks, suggesting the RL training method is highly effective.
2. **Benchmark Difficulty:** The AIME2024 benchmark yields much lower accuracy scores across all models, suggesting it is a more difficult test of mathematical reasoning.
3. **Token Length Advantage:** The k1.5 model family consistently operates at higher token lengths than the other models shown (except `deepseek-v3` on AIME2024), and this correlates with higher performance.
4. **Model Comparison:** On both benchmarks, the plotted `gpt-4-0513` and `Claude 3.5` points show lower accuracy than the k1.5 family and `deepseek-v3`. `qwen25-72B-inst` performs in the middle range.
5. **Scaling Effect:** Within the k1.5 family, moving from `k1.5-shortest` to `k1.5-long` generally involves an increase in both token length and accuracy.
### Interpretation
The data suggests a strong relationship between model context length (token length) and performance on complex mathematical reasoning tasks, at least within the `k1.5` model family. The consistent superiority of the `k1.5-short w/ rl` variant highlights the potential of reinforcement learning techniques to boost reasoning capabilities beyond what is achieved with other methods like DPO (Direct Preference Optimization) or merge strategies.
The stark difference in accuracy ranges between MATH500 and AIME2024 indicates these benchmarks test different levels or types of mathematical difficulty. AIME (American Invitational Mathematics Examination) problems are known to be highly challenging, which aligns with the lower scores. The fact that the `k1.5-long` model, with the largest context, performs best on the harder AIME2024 benchmark could imply that longer context windows are particularly beneficial for solving more complex, multi-step problems that require holding and manipulating more information.
The plots do not show a simple linear scaling law for all models, as the blue comparison points are scattered. This implies that factors other than raw token length—such as training data, architecture, and fine-tuning methods (like RL, DPO)—are critical determinants of performance. The visualization effectively argues for the efficacy of the `k1.5` approach, particularly its RL variant, in advancing the state-of-the-art for mathematical reasoning in AI.
DECODING INTELLIGENCE...