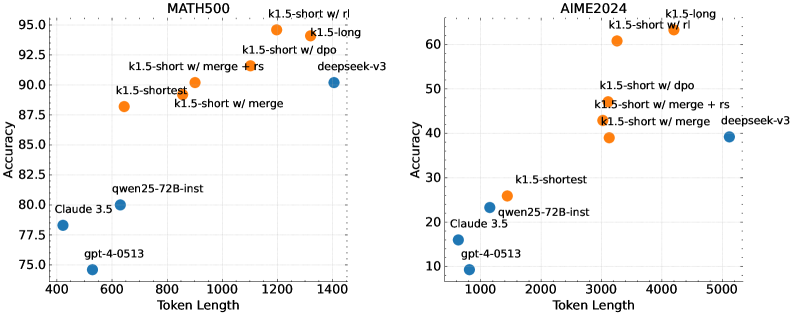
## Line Chart: Model Performance Comparison (MATH500 vs AIME2024)
### Overview
The image contains two side-by-side line charts comparing model performance across two datasets: MATH500 (left) and AIME2024 (right). Both charts plot **Accuracy** (y-axis) against **Token Length** (x-axis), with distinct data points representing different model configurations. The charts use orange and blue markers to differentiate model types.
---
### Components/Axes
#### MATH500 Chart (Left)
- **X-axis (Token Length)**: 400–1400 (linear scale)
- **Y-axis (Accuracy)**: 75–95 (linear scale)
- **Legend**:
- Orange: k1.5 variants (short/long, merge, dpo, rs, rl)
- Blue: qwen25-72B-inst, Claude 3.5, gpt-4-0513
- **Data Points**:
- k1.5-short (600 tokens, 88% accuracy)
- k1.5-shortest (900 tokens, 87.5% accuracy)
- k1.5-short w/ merge (1000 tokens, 90% accuracy)
- k1.5-short w/ merge + rs (1100 tokens, 92.5% accuracy)
- k1.5-long (1200 tokens, 94% accuracy)
- k1.5-short w/ rl (1300 tokens, 93% accuracy)
- qwen25-72B-inst (700 tokens, 80% accuracy)
- Claude 3.5 (500 tokens, 78% accuracy)
- gpt-4-0513 (450 tokens, 75% accuracy)
#### AIME2024 Chart (Right)
- **X-axis (Token Length)**: 1000–5000 (linear scale)
- **Y-axis (Accuracy)**: 10–60 (linear scale)
- **Legend**:
- Orange: k1.5 variants (short/long, merge, dpo, rs)
- Blue: qwen25-72B-inst, Claude 3.5, deepseek-v3
- **Data Points**:
- k1.5-shortest (1500 tokens, 25% accuracy)
- k1.5-short w/ merge (2000 tokens, 45% accuracy)
- k1.5-short w/ merge + rs (2500 tokens, 48% accuracy)
- k1.5-long (3000 tokens, 55% accuracy)
- k1.5-short w/ dpo (3500 tokens, 50% accuracy)
- k1.5-short w/ rl (4000 tokens, 58% accuracy)
- qwen25-72B-inst (1200 tokens, 20% accuracy)
- Claude 3.5 (1000 tokens, 18% accuracy)
- deepseek-v3 (5000 tokens, 45% accuracy)
---
### Detailed Analysis
#### MATH500 Trends
- **k1.5-short variants** dominate the chart, with accuracy increasing as token length grows (600–1300 tokens). The **merge + rs** configuration achieves the highest accuracy (92.5% at 1100 tokens).
- **qwen25-72B-inst** (700 tokens, 80%) and **Claude 3.5** (500 tokens, 78%) underperform compared to k1.5 models.
- **gpt-4-0513** (450 tokens, 75%) has the lowest accuracy.
#### AIME2024 Trends
- **k1.5-short w/ merge + rs** (2500 tokens, 48%) and **k1.5-long** (3000 tokens, 55%) show the best performance.
- **deepseek-v3** (5000 tokens, 45%) matches the k1.5-short w/ merge + rs model despite longer token length.
- **qwen25-72B-inst** (1200 tokens, 20%) and **Claude 3.5** (1000 tokens, 18%) lag significantly.
---
### Key Observations
1. **MATH500**:
- k1.5-short variants achieve >87% accuracy, outperforming other models.
- Merge + rs configuration yields the highest accuracy (92.5%).
- Longer token lengths (1200–1300) correlate with higher accuracy.
2. **AIME2024**:
- k1.5-short w/ merge + rs (2500 tokens) and k1.5-long (3000 tokens) achieve >50% accuracy.
- deepseek-v3 (5000 tokens) matches k1.5-short w/ merge + rs despite longer token length.
- Accuracy plateaus at ~55% for k1.5-long and k1.5-short w/ rl.
3. **Outliers**:
- **MATH500**: k1.5-short w/ merge + rs (92.5%) exceeds all other models.
- **AIME2024**: deepseek-v3 (45%) outperforms k1.5-short w/ merge (48%) despite longer token length.
---
### Interpretation
The data suggests that **model architecture optimizations** (e.g., merge + rs) significantly impact performance on MATH500, while **token length** plays a stronger role in AIME2024. The k1.5-short variants excel in MATH500 due to efficient token utilization, whereas AIME2024 requires longer token processing for higher accuracy. The deepseek-v3 model’s performance in AIME2024 indicates that specialized architectures can compete with optimized k1.5 variants despite higher computational costs. The divergence in trends between datasets highlights the importance of task-specific model tuning.