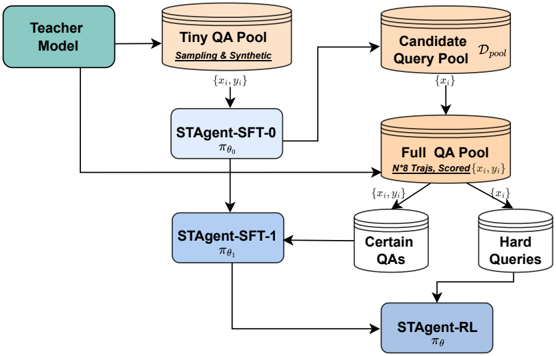
## Data Flow Diagram: STAgent Training Process
### Overview
The image is a data flow diagram illustrating the training process of an STAgent model. It shows the flow of data between different components, including a Teacher Model, QA Pools, and various STAgent stages (SFT-0, SFT-1, and RL).
### Components/Axes
* **Teacher Model:** A teal-colored rectangle at the top-left, representing the initial model used for generating training data.
* **Tiny QA Pool:** A tan-colored cylinder labeled "Tiny QA Pool" with the description "Sampling & Synthetic" underneath. It receives input from the Teacher Model and outputs data in the form of `{xi, yi}`.
* **Candidate Query Pool:** A tan-colored cylinder labeled "Candidate Query Pool" with the notation "Dpool" to the right. It feeds into the Full QA Pool.
* **Full QA Pool:** A tan-colored cylinder labeled "Full QA Pool" with the description "N°8 Trajs, Scored {xi, yi}" underneath. It receives input from both the Tiny QA Pool and the Candidate Query Pool. It splits into "Certain QAs" and "Hard Queries".
* **Certain QAs:** A white-colored cylinder labeled "Certain QAs". It receives input from the Full QA Pool.
* **Hard Queries:** A white-colored cylinder labeled "Hard Queries". It receives input from the Full QA Pool.
* **STAgent-SFT-0:** A light blue rectangle labeled "STAgent-SFT-0" with "πθ0" underneath. It receives input from the Tiny QA Pool and the Teacher Model.
* **STAgent-SFT-1:** A light blue rectangle labeled "STAgent-SFT-1" with "πθ1" underneath. It receives input from STAgent-SFT-0.
* **STAgent-RL:** A light blue rectangle labeled "STAgent-RL" with "πθ" underneath. It receives input from STAgent-SFT-1, Certain QAs, and Hard Queries.
### Detailed Analysis or Content Details
* The Teacher Model feeds directly into the Tiny QA Pool and STAgent-SFT-0.
* The Tiny QA Pool, described as "Sampling & Synthetic", outputs data `{xi, yi}` to STAgent-SFT-0.
* The Candidate Query Pool feeds into the Full QA Pool.
* The Full QA Pool, described as "N°8 Trajs, Scored {xi, yi}", splits into "Certain QAs" and "Hard Queries".
* STAgent-SFT-0 feeds into STAgent-SFT-1.
* STAgent-SFT-1 feeds into STAgent-RL.
* Both "Certain QAs" and "Hard Queries" feed into STAgent-RL.
### Key Observations
* The diagram illustrates a multi-stage training process for an STAgent model.
* The Teacher Model provides initial data and guidance.
* QA Pools are used to store and filter question-answer pairs.
* The STAgent model is refined through supervised fine-tuning (SFT) and reinforcement learning (RL).
### Interpretation
The diagram depicts a training pipeline where a Teacher Model generates synthetic data for initial training. This data is stored in a Tiny QA Pool. The STAgent is then fine-tuned in stages (SFT-0 and SFT-1). A Candidate Query Pool is used to create a Full QA Pool, which is then split into "Certain QAs" and "Hard Queries" to provide targeted training data for the STAgent-RL stage. This suggests an active learning approach where the model is trained on both easy and difficult examples to improve its overall performance. The use of a Teacher Model and staged training indicates a strategy to improve the model's robustness and generalization capabilities.