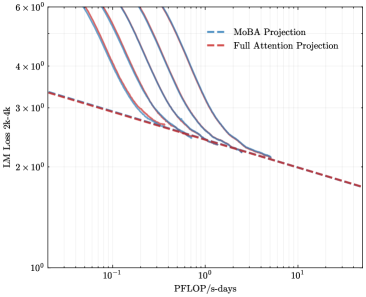
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph illustrates how loss (measured in "LM Loss 2k-4k") decreases as computational throughput (PFlOP/s-days) increases.
### Components/Axes
- **X-axis**: Labeled "PFlOP/s-days" with a logarithmic scale ranging from 10⁻¹ to 10¹.
- **Y-axis**: Labeled "LM Loss 2k-4k" with a logarithmic scale from 10⁰ to 6×10⁰.
- **Legend**: Positioned in the top-right corner, associating:
- Blue dashed line → "MoBA Projection"
- Red dashed line → "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately 5×10⁰ LM Loss when PFlOP/s-days = 10⁻¹.
- Decreases sharply, intersecting the Full Attention Projection near PFlOP/s-days = 10⁰ (x=1) and LM Loss ≈ 2.5×10⁰.
- Continues downward, ending near 1.8×10⁰ at PFlOP/s-days = 10¹.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins slightly lower than MoBA at ~4.5×10⁰ LM Loss for PFlOP/s-days = 10⁻¹.
- Decreases linearly, maintaining a steeper slope than MoBA after their intersection.
- Ends at ~1.5×10⁰ LM Loss for PFlOP/s-days = 10¹.
### Key Observations
- **Intersection Point**: The two projections converge at ~PFlOP/s-days = 10⁰, where LM Loss ≈ 2.5×10⁰.
- **Divergence**: MoBA Projection maintains higher efficiency (lower loss) than Full Attention Projection for PFlOP/s-days > 10⁰.
- **Logarithmic Trends**: Both lines exhibit exponential decay, but MoBA’s decay rate slows after the intersection.
### Interpretation
The graph suggests that MoBA Projection achieves comparable or superior computational efficiency to Full Attention Projection at higher throughput levels (PFlOP/s-days > 10⁰). The intersection at PFlOP/s-days = 10⁰ implies a critical threshold where MoBA’s architectural advantages (e.g., reduced attention complexity) become dominant. This could inform hardware/software optimization strategies for large-scale language models, prioritizing MoBA for high-throughput scenarios.