\n
## Violin Plot: US Foreign Policy Accuracy
### Overview
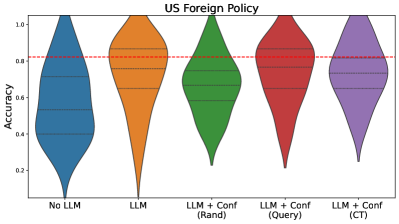
This image presents a violin plot comparing the accuracy of different approaches related to Large Language Models (LLMs) in the context of US Foreign Policy. The plot displays the distribution of accuracy scores for five different methods. A horizontal dashed red line indicates a threshold accuracy level.
### Components/Axes
* **Title:** "US Foreign Policy" (centered at the top)
* **Y-axis Label:** "Accuracy" (left side, ranging from approximately 0.2 to 1.0)
* **X-axis Categories:**
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Horizontal Line:** A dashed red line at approximately 0.8 accuracy.
* **Violin Plots:** Five violin plots, one for each category on the x-axis. Each plot represents the distribution of accuracy scores for that method.
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each method. The width of each violin represents the density of scores at different accuracy levels.
* **No LLM (Blue):** The distribution is centered around approximately 0.6 accuracy, with a range from roughly 0.2 to 1.0. The plot is relatively wide, indicating a significant spread in accuracy scores.
* **LLM (Orange):** The distribution is centered around approximately 0.8 accuracy, with a range from roughly 0.4 to 1.0. It is also relatively wide, but shifted to the right compared to "No LLM".
* **LLM + Conf (Rand) (Green):** The distribution is centered around approximately 0.7 accuracy, with a range from roughly 0.3 to 0.9. It is narrower than the previous two, suggesting less variability.
* **LLM + Conf (Query) (Red):** The distribution is centered around approximately 0.8 accuracy, with a range from roughly 0.5 to 1.0. It is similar to the "LLM" distribution in terms of central tendency.
* **LLM + Conf (CT) (Purple):** The distribution is centered around approximately 0.7 accuracy, with a range from roughly 0.3 to 0.9. It is similar to the "LLM + Conf (Rand)" distribution.
The dashed red line at approximately 0.8 accuracy serves as a benchmark. The "LLM" and "LLM + Conf (Query)" distributions show a substantial portion of scores above this line.
### Key Observations
* Using an LLM generally improves accuracy compared to not using an LLM ("No LLM").
* The "LLM + Conf (Query)" method appears to perform similarly to the "LLM" method.
* The "LLM + Conf (Rand)" and "LLM + Conf (CT)" methods show slightly lower central tendencies compared to the "LLM" method.
* There is considerable variability in accuracy scores within each method, as indicated by the width of the violin plots.
### Interpretation
The data suggests that incorporating LLMs can enhance accuracy in the context of US Foreign Policy analysis. The "LLM" and "LLM + Conf (Query)" methods demonstrate the highest accuracy, with a significant proportion of scores exceeding the 0.8 benchmark. The addition of "Confidence" information, using either a random approach ("Rand"), query-based approach ("Query"), or a "CT" method, does not consistently improve performance over simply using the LLM. The variability within each method suggests that the performance of these approaches can be sensitive to the specific input or task. The violin plots provide a visual representation of the distribution of accuracy scores, allowing for a comparison of the central tendency and spread of each method. The horizontal line provides a clear threshold for evaluating performance.