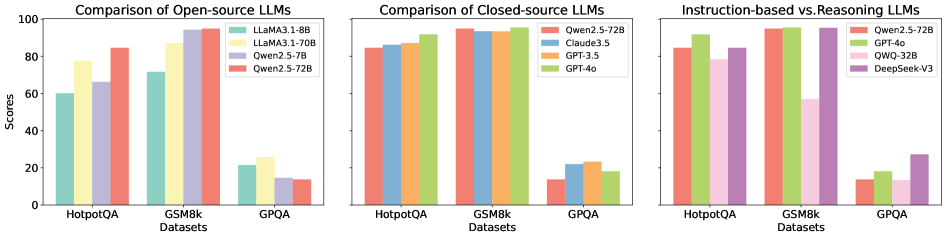
## Bar Chart: LLM Performance Comparison
### Overview
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, ranging from 0 to 100.
### Components/Axes
* **Titles:**
* Left Chart: "Comparison of Open-source LLMs"
* Middle Chart: "Comparison of Closed-source LLMs"
* Right Chart: "Instruction-based vs. Reasoning LLMs"
* **Y-axis:**
* Label: "Scores"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-axis:**
* Label: "Datasets"
* Categories: HotpotQA, GSM8k, GPQA
* **Legends:**
* Left Chart (Open-source LLMs):
* Light Green: LLaMA3.1-8B
* Yellow: LLaMA3.1-70B
* Light Purple: Qwen2.5-7B
* Salmon: Qwen2.5-72B
* Middle Chart (Closed-source LLMs):
* Salmon: Qwen2.5-72B
* Light Blue: Claude3.5
* Orange: GPT-3.5
* Light Green: GPT-4o
* Right Chart (Instruction-based vs. Reasoning LLMs):
* Salmon: Qwen2.5-72B
* Light Green: GPT-4o
* Pink: QWQ-32B
* Purple: DeepSeek-V3
### Detailed Analysis
**Left Chart: Comparison of Open-source LLMs**
* **LLaMA3.1-8B (Light Green):**
* HotpotQA: ~60
* GSM8k: ~78
* GPQA: ~22
* **LLaMA3.1-70B (Yellow):**
* HotpotQA: ~78
* GSM8k: ~87
* GPQA: ~24
* **Qwen2.5-7B (Light Purple):**
* HotpotQA: ~67
* GSM8k: ~94
* GPQA: ~22
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~84
* GSM8k: ~94
* GPQA: ~23
**Middle Chart: Comparison of Closed-source LLMs**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~86
* GSM8k: ~94
* GPQA: ~16
* **Claude3.5 (Light Blue):**
* HotpotQA: ~84
* GSM8k: ~93
* GPQA: ~22
* **GPT-3.5 (Orange):**
* HotpotQA: ~88
* GSM8k: ~94
* GPQA: ~24
* **GPT-4o (Light Green):**
* HotpotQA: ~92
* GSM8k: ~95
* GPQA: ~23
**Right Chart: Instruction-based vs. Reasoning LLMs**
* **Qwen2.5-72B (Salmon):**
* HotpotQA: ~84
* GSM8k: ~94
* GPQA: ~16
* **GPT-4o (Light Green):**
* HotpotQA: ~93
* GSM8k: ~95
* GPQA: ~22
* **QWQ-32B (Pink):**
* HotpotQA: ~80
* GSM8k: ~94
* GPQA: ~18
* **DeepSeek-V3 (Purple):**
* HotpotQA: ~84
* GSM8k: ~94
* GPQA: ~28
### Key Observations
* **GSM8k Performance:** All models perform exceptionally well on the GSM8k dataset, with scores consistently above 90.
* **GPQA Performance:** All models struggle with the GPQA dataset, with scores generally below 30.
* **Open-source vs. Closed-source:** Closed-source models generally outperform open-source models on the HotpotQA dataset.
* **Instruction-based vs. Reasoning:** GPT-4o shows a slight edge on HotpotQA and GSM8k compared to other models in this category. DeepSeek-V3 shows a higher score on GPQA compared to the other models.
### Interpretation
The charts provide a comparative analysis of LLM performance across different datasets and model types. The high scores on GSM8k suggest that all models are proficient in tasks related to this dataset, while the low scores on GPQA indicate a common weakness in handling the complexities of that dataset. The comparison between open-source and closed-source models highlights the performance advantages of closed-source models in certain areas. The instruction-based vs. reasoning comparison shows the relative strengths and weaknesses of different models in these categories. The data suggests that model selection should be tailored to the specific task and dataset, as different models exhibit varying levels of proficiency.