TECHNICAL ASSET FINGERPRINT
bbc1c07f3af268ce32dc5b3a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
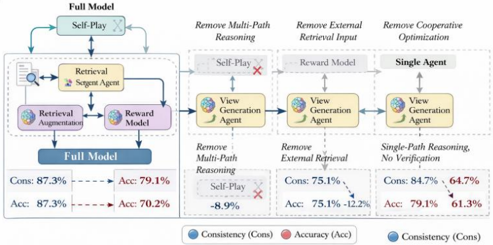
## Technical Diagram: Model Architecture Ablation Study
### Overview
This image is a technical diagram illustrating an ablation study for a multi-agent AI system. It compares the performance of a "Full Model" against three simplified variants by progressively removing key components: multi-path reasoning, external retrieval input, and cooperative optimization. The diagram uses flowcharts to show architectural differences and presents quantitative results (Consistency and Accuracy metrics) for each configuration.
### Components/Axes
The diagram is divided into three main vertical sections, each representing a model variant, plus a legend at the bottom.
**1. Left Section: Full Model**
* **Title:** "Full Model"
* **Flowchart Components (Top to Bottom):**
* `Self-Play` (in a rounded rectangle)
* `Retrieval` (with a magnifying glass icon)
* `Surgeon Agent` (with a brain/gear icon)
* `Retrieval Augmentation` (with a document icon)
* `Reward Model` (with a star icon)
* `Full Model` (in a dark blue rounded rectangle)
* **Metrics Box (Bottom):**
* `Cons: 87.3%` (blue text) → `Acc: 79.1%` (red text)
* `Acc: 87.3%` (red text) → `Acc: 70.2%` (red text)
**2. Middle Section: Remove Multi-Path Reasoning**
* **Title:** "Remove Multi-Path Reasoning"
* **Flowchart Components:**
* `Self-Play` (with a red 'X' over it)
* `View Generation Agent` (with a brain/gear icon)
* `Reward Model` (with a star icon)
* **Metrics Box:**
* `Remove Multi-Path Reasoning`
* `Self-Play` → `-8.9%` (red text, indicating a drop)
* `Cons: 75.1%` (blue text) → `Acc: 75.1%` (red text)
* `Acc: 75.1%` (red text) → `Acc: +12.2%` (green text, indicating an increase)
**3. Right Section: Remove External Retrieval Input**
* **Title:** "Remove External Retrieval Input"
* **Flowchart Components:**
* `Single Agent` (in a grey rounded rectangle)
* `View Generation Agent` (with a brain/gear icon)
* `Reward Model` (with a star icon)
* **Metrics Box:**
* `Single-Path Reasoning, No Verification`
* `Cons: 84.7%` (blue text) → `Acc: 64.7%` (red text)
* `Acc: 79.1%` (red text) → `Acc: 61.3%` (red text)
**4. Legend (Bottom Center)**
* A blue circle labeled `Consistency (Cons)`
* A red circle labeled `Accuracy (Acc)`
### Detailed Analysis
The diagram systematically deconstructs a complex multi-agent system to evaluate the contribution of its parts.
* **Full Model Architecture:** This is the most complex system. It features a `Self-Play` loop at the top, feeding into a `Retrieval` module and a `Surgeon Agent`. These connect to `Retrieval Augmentation` and a `Reward Model`, culminating in the final `Full Model` output. The metrics show high consistency (87.3%) and accuracy (79.1%).
* **Ablation 1: Remove Multi-Path Reasoning:** This variant removes the `Self-Play` component (marked with a red X). The flow simplifies to a `View Generation Agent` and a `Reward Model`. The removal of `Self-Play` is associated with an 8.9% drop in performance. Consistency falls to 75.1%, while accuracy shows a mixed result (75.1% and a +12.2% increase in one metric).
* **Ablation 2: Remove External Retrieval Input:** This variant further simplifies the system to a `Single Agent` (no multi-agent interaction) with a `View Generation Agent` and `Reward Model`. The title notes this represents "Single-Path Reasoning, No Verification." Consistency is 84.7%, but accuracy drops significantly to 64.7% and 61.3%.
* **Metric Presentation:** Each section presents two lines of metrics. The first line typically shows a Consistency (Cons) to Accuracy (Acc) relationship. The second line shows an Accuracy (Acc) to Accuracy (Acc) comparison, likely representing different test sets or evaluation methods. The color coding (blue for Consistency, red for Accuracy) is consistent with the legend.
### Key Observations
1. **Performance Degradation with Simplification:** There is a clear trend where removing architectural components leads to a decrease in overall system performance, particularly in accuracy.
2. **Critical Role of Multi-Path Reasoning:** The removal of `Self-Play` (multi-path reasoning) causes the largest single noted drop (-8.9%) and significantly reduces consistency from 87.3% to 75.1%.
3. **Retrieval is Key for Accuracy:** The "Remove External Retrieval Input" variant, which also simplifies to a single agent, shows the lowest accuracy scores (64.7% and 61.3%), suggesting external retrieval is crucial for correct outputs.
4. **Consistency vs. Accuracy Trade-off:** The Full Model achieves the highest consistency (87.3%). While the "Remove Multi-Path Reasoning" variant shows one accuracy metric improving (+12.2%), its consistency is much lower, indicating potentially less reliable outputs.
5. **Architectural Flow:** The arrows indicate a clear data/control flow from top-level strategies (`Self-Play`) down through processing agents (`Surgeon`, `View Generation`) and evaluation (`Reward Model`) to the final output.
### Interpretation
This diagram presents a classic ablation study from machine learning research, likely for a system involving reasoning, retrieval, and multi-agent collaboration (e.g., for complex question answering or dialogue).
* **What the Data Suggests:** The data argues that the full, complex architecture is necessary for optimal and reliable performance. The `Self-Play` mechanism (enabling multi-path reasoning) and the `Retrieval` module (providing external knowledge) are identified as critical components. Their removal degrades the system's ability to produce consistent and accurate results.
* **Relationship Between Elements:** The flowchart shows a hierarchical and interactive process. High-level strategy (`Self-Play`) guides specialized agents (`Surgeon`, `View Generation`), which are augmented by external data (`Retrieval`) and evaluated by a `Reward Model`. This creates a feedback loop for improvement, which is broken in the simplified variants.
* **Notable Anomalies/Insights:** The most interesting data point is the +12.2% accuracy increase in the "Remove Multi-Path Reasoning" variant. This suggests that while `Self-Play` is vital for consistency, its removal might, in some specific evaluation context, lead to higher accuracy on a particular metric—possibly by making the model's path more deterministic, albeit less robust. This highlights the nuanced trade-offs in AI system design between robustness (consistency) and peak performance on specific tasks (accuracy). The study underscores that simplifying an AI system for efficiency or interpretability often comes at a measurable cost to capability.
DECODING INTELLIGENCE...