TECHNICAL ASSET FINGERPRINT
bc1a38c805ead0456cec75c3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
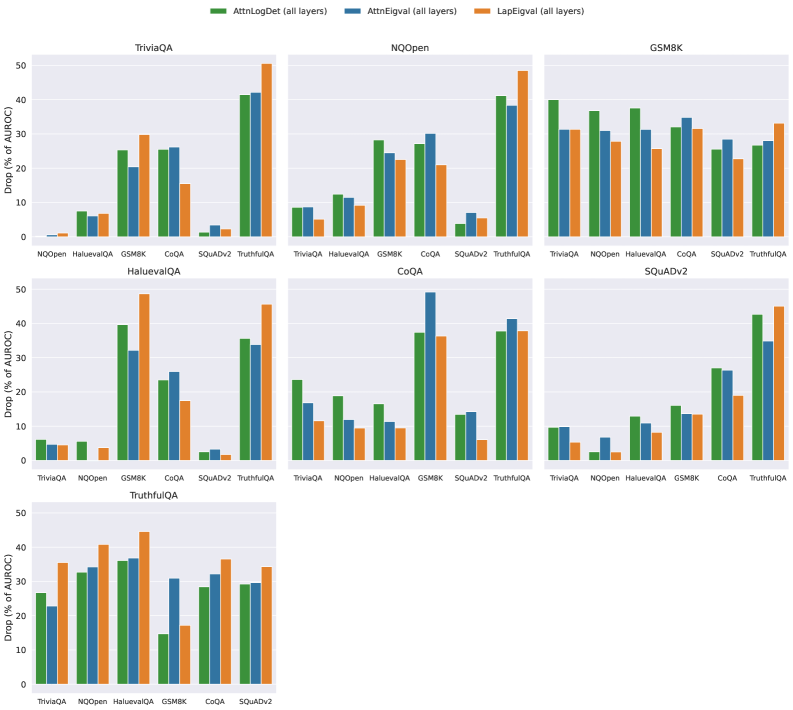
## Grouped Bar Charts: Performance Drop Analysis Across Datasets
### Overview
The image displays a composite figure containing seven individual grouped bar charts arranged in a 3x3 grid (with two empty slots in the bottom row). Each chart evaluates the performance drop of three different methods when applied to various question-answering or reasoning datasets. The primary metric is the percentage drop in Area Under the Risk-Coverage curve (AURC), where a lower value indicates better performance retention.
### Components/Axes
- **Legend**: Positioned at the top center of the entire figure. It defines three methods:
- **AttnLogDet (all layers)**: Represented by green bars.
- **AttnEigval (all layers)**: Represented by blue bars.
- **LapEigval (all layers)**: Represented by orange bars.
- **Y-Axis (Common to all charts)**: Labeled **"Drop (% of AURC)"**. The scale ranges from 0 to 50, with major tick marks at intervals of 10.
- **X-Axis (Varies per chart)**: Lists different datasets used for evaluation. The specific datasets are: TriviaQA, NQOpen, HaluEvalQA, GSM8K, CoQA, SQuADv2, and TruthfulQA.
- **Chart Titles**: Each subplot has a title indicating the primary dataset under analysis (e.g., "TriviaQA", "NQOpen").
### Detailed Analysis
The following is a chart-by-chart breakdown of the estimated values. All values are approximate visual readings from the bar heights.
**1. Chart: TriviaQA (Top-Left)**
* **X-Axis Categories**: NQOpen, HaluEvalQA, GSM8K, CoQA, SQuADv2, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **NQOpen**: AttnLogDet ~1%, AttnEigval ~1%, LapEigval ~1%.
* **HaluEvalQA**: AttnLogDet ~7%, AttnEigval ~6%, LapEigval ~6%.
* **GSM8K**: AttnLogDet ~25%, AttnEigval ~20%, LapEigval ~29%.
* **CoQA**: AttnLogDet ~26%, AttnEigval ~25%, LapEigval ~15%.
* **SQuADv2**: AttnLogDet ~3%, AttnEigval ~3%, LapEigval ~2%.
* **TruthfulQA**: AttnLogDet ~42%, AttnEigval ~43%, LapEigval ~50%.
**2. Chart: NQOpen (Top-Middle)**
* **X-Axis Categories**: TriviaQA, HaluEvalQA, GSM8K, CoQA, SQuADv2, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~8%, AttnEigval ~8%, LapEigval ~5%.
* **HaluEvalQA**: AttnLogDet ~12%, AttnEigval ~11%, LapEigval ~10%.
* **GSM8K**: AttnLogDet ~28%, AttnEigval ~24%, LapEigval ~22%.
* **CoQA**: AttnLogDet ~27%, AttnEigval ~29%, LapEigval ~21%.
* **SQuADv2**: AttnLogDet ~4%, AttnEigval ~4%, LapEigval ~5%.
* **TruthfulQA**: AttnLogDet ~41%, AttnEigval ~38%, LapEigval ~48%.
**3. Chart: GSM8K (Top-Right)**
* **X-Axis Categories**: TriviaQA, NQOpen, HaluEvalQA, CoQA, SQuADv2, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~40%, AttnEigval ~31%, LapEigval ~31%.
* **NQOpen**: AttnLogDet ~37%, AttnEigval ~31%, LapEigval ~27%.
* **HaluEvalQA**: AttnLogDet ~38%, AttnEigval ~31%, LapEigval ~25%.
* **CoQA**: AttnLogDet ~32%, AttnEigval ~35%, LapEigval ~32%.
* **SQuADv2**: AttnLogDet ~26%, AttnEigval ~28%, LapEigval ~22%.
* **TruthfulQA**: AttnLogDet ~26%, AttnEigval ~28%, LapEigval ~33%.
**4. Chart: HaluEvalQA (Middle-Left)**
* **X-Axis Categories**: TriviaQA, NQOpen, GSM8K, CoQA, SQuADv2, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~6%, AttnEigval ~5%, LapEigval ~5%.
* **NQOpen**: AttnLogDet ~6%, AttnEigval ~5%, LapEigval ~4%.
* **GSM8K**: AttnLogDet ~39%, AttnEigval ~32%, LapEigval ~48%.
* **CoQA**: AttnLogDet ~26%, AttnEigval ~24%, LapEigval ~17%.
* **SQuADv2**: AttnLogDet ~3%, AttnEigval ~3%, LapEigval ~2%.
* **TruthfulQA**: AttnLogDet ~35%, AttnEigval ~33%, LapEigval ~45%.
**5. Chart: CoQA (Middle-Center)**
* **X-Axis Categories**: TriviaQA, NQOpen, HaluEvalQA, GSM8K, SQuADv2, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~23%, AttnEigval ~16%, LapEigval ~11%.
* **NQOpen**: AttnLogDet ~19%, AttnEigval ~12%, LapEigval ~10%.
* **HaluEvalQA**: AttnLogDet ~16%, AttnEigval ~11%, LapEigval ~10%.
* **GSM8K**: AttnLogDet ~37%, AttnEigval ~49%, LapEigval ~36%.
* **SQuADv2**: AttnLogDet ~14%, AttnEigval ~13%, LapEigval ~6%.
* **TruthfulQA**: AttnLogDet ~37%, AttnEigval ~41%, LapEigval ~38%.
**6. Chart: SQuADv2 (Middle-Right)**
* **X-Axis Categories**: TriviaQA, NQOpen, HaluEvalQA, GSM8K, CoQA, TruthfulQA.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~10%, AttnEigval ~9%, LapEigval ~5%.
* **NQOpen**: AttnLogDet ~2%, AttnEigval ~7%, LapEigval ~1%.
* **HaluEvalQA**: AttnLogDet ~12%, AttnEigval ~9%, LapEigval ~8%.
* **GSM8K**: AttnLogDet ~16%, AttnEigval ~13%, LapEigval ~13%.
* **CoQA**: AttnLogDet ~26%, AttnEigval ~27%, LapEigval ~19%.
* **TruthfulQA**: AttnLogDet ~42%, AttnEigval ~35%, LapEigval ~45%.
**7. Chart: TruthfulQA (Bottom-Left)**
* **X-Axis Categories**: TriviaQA, NQOpen, HaluEvalQA, GSM8K, CoQA, SQuADv2.
* **Data Points (Approx. Drop %)**:
* **TriviaQA**: AttnLogDet ~26%, AttnEigval ~22%, LapEigval ~36%.
* **NQOpen**: AttnLogDet ~33%, AttnEigval ~34%, LapEigval ~41%.
* **HaluEvalQA**: AttnLogDet ~36%, AttnEigval ~37%, LapEigval ~45%.
* **GSM8K**: AttnLogDet ~15%, AttnEigval ~31%, LapEigval ~17%.
* **CoQA**: AttnLogDet ~28%, AttnEigval ~32%, LapEigval ~36%.
* **SQuADv2**: AttnLogDet ~29%, AttnEigval ~29%, LapEigval ~34%.
### Key Observations
1. **Dataset Difficulty**: The **TruthfulQA** dataset consistently induces the highest performance drops across nearly all charts and methods, often exceeding 35%. Conversely, **SQuADv2** and **NQOpen** often show the lowest drops, frequently below 10%.
2. **Method Performance**: No single method is universally superior.
* **LapEigval (orange)** frequently shows the highest drop (worst performance) on challenging datasets like TruthfulQA and GSM8K (e.g., ~50% drop in TriviaQA chart for TruthfulQA).
* **AttnLogDet (green)** and **AttnEigval (blue)** often perform similarly, but their relative performance flips depending on the dataset. For example, in the CoQA chart for GSM8K, AttnEigval has a notably higher drop (~49%) than the other two.
3. **Cross-Dataset Generalization**: The charts reveal how methods trained or analyzed on one dataset (chart title) perform when evaluated on others (x-axis). Performance drops are generally lower when the evaluation dataset matches the chart's title dataset, suggesting some degree of domain specificity.
### Interpretation
This figure presents a robustness or generalization analysis of three attention-based or spectral analysis methods (AttnLogDet, AttnEigval, LapEigval) across seven diverse question-answering benchmarks. The "Drop (% of AURC)" metric quantifies the degradation in model performance when these methods are applied, likely as a form of model pruning, compression, or intervention.
The data suggests that the **complexity and nature of the target dataset are the primary drivers of performance loss**. Reasoning-heavy datasets like GSM8K (math) and TruthfulQA (adversarial factuality) cause significant degradation for all methods, indicating that the analyzed model components (captured by "all layers") are critical for these tasks. In contrast, more extractive or retrieval-focused tasks like SQuADv2 are less affected.
The variability in method performance implies that the underlying mathematical properties each method captures (log-determinant, eigenvalues of attention, Laplacian eigenvalues) have different sensitivities to the type of reasoning required. The high drop for LapEigval on TruthfulQA might indicate that graph-spectral properties of the model are particularly important for handling adversarial or truthful responses. This analysis is crucial for understanding which model components are essential for different cognitive tasks and for guiding the development of more efficient and robust models.
DECODING INTELLIGENCE...