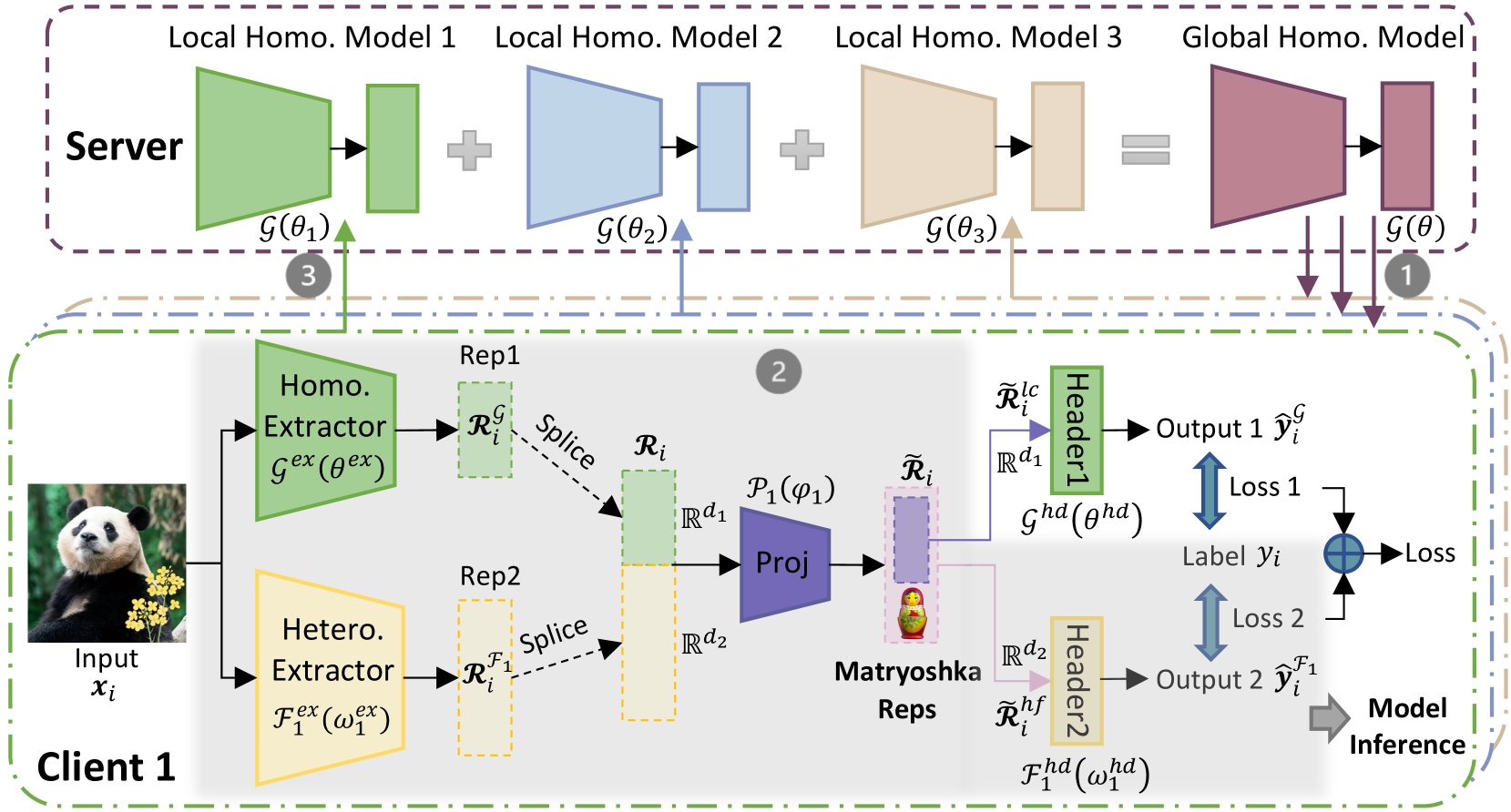
## Diagram: Federated Learning Architecture with Local and Global Model Aggregation
### Overview
The diagram illustrates a federated learning system where multiple clients (e.g., Client 1) train local homogeneous models on their data, which are aggregated into a global model on a server. The client-side workflow includes input processing, representation extraction, projection, and loss calculation for model inference. Key components include local homogeneous models, a global model, extractors, projectors, and Matryoshka representations.
---
### Components/Axes
#### Server-Side Components
1. **Local Homogeneous Models**:
- **Model 1**: Green block labeled `g(θ₁)`.
- **Model 2**: Blue block labeled `g(θ₂)`.
- **Model 3**: Beige block labeled `g(θ₃)`.
2. **Global Homogeneous Model**: Purple block labeled `g(θ)`, formed by aggregating local models.
3. **Flow**: Arrows indicate aggregation (`+`) from local models to the global model.
#### Client-Side Components (Client 1)
1. **Input**: Image of a panda labeled `Input x_i`.
2. **Homo. Extractor**: Green block labeled `g_ex(θ_ex)`.
3. **Hetero. Extractor**: Yellow block labeled `F₁_ex(ω₁_ex)`.
4. **Representations**:
- **Rep1**: Green block labeled `R_i^g`.
- **Rep2**: Yellow block labeled `R_i^F1`.
5. **Projection**: Purple block labeled `P₁(φ₁)`.
6. **Matryoshka Reps**: Purple block with nested doll icon.
7. **Headers**:
- **Header1**: Green block labeled `g_hd(θ_hd)`.
- **Header2**: Yellow block labeled `F₁_hd(ω₁_hd)`.
8. **Outputs**:
- **Output 1**: `ŷ_i^g` (green arrow).
- **Output 2**: `ŷ_i^F1` (yellow arrow).
9. **Loss Functions**:
- **Loss 1**: Blue arrow labeled `Loss` (global model).
- **Loss 2**: Blue arrow labeled `Loss` (heterogeneous model).
10. **Model Inference**: Gray arrow labeled `Model Inference`.
---
### Detailed Analysis
#### Server-Side
- **Local Models**: Three distinct local homogeneous models (`g(θ₁)`, `g(θ₂)`, `g(θ₃)`) are trained independently on client data.
- **Global Model**: Aggregated from local models via summation (`+`), resulting in `g(θ)`.
#### Client-Side
1. **Input Processing**:
- The panda image (`x_i`) is processed by two extractors:
- **Homo. Extractor**: Generates homogeneous representation `R_i^g`.
- **Hetero. Extractor**: Generates heterogeneous representation `R_i^F1`.
2. **Representation Splicing**:
- `R_i^g` and `R_i^F1` are spliced into a combined representation `R_i`.
3. **Projection**:
- Combined representation `R_i` is projected via `P₁(φ₁)` into a latent space.
4. **Matryoshka Reps**:
- Nested representations (`Ũ_i`, `Ũ_i^F1`) are derived, likely for hierarchical feature learning.
5. **Headers**:
- **Header1**: Processes `Ũ_i` via `g_hd(θ_hd)`.
- **Header2**: Processes `Ũ_i^F1` via `F₁_hd(ω₁_hd)`.
6. **Loss Calculation**:
- **Loss 1**: Measures discrepancy between `ŷ_i^g` and true label `y_i`.
- **Loss 2**: Measures discrepancy between `ŷ_i^F1` and true label `y_i`.
---
### Key Observations
1. **Model Heterogeneity**: The system handles both homogeneous (`g(θ)`) and heterogeneous (`F₁(ω)`) feature extractors.
2. **Matryoshka Reps**: Suggests a nested representation strategy, possibly for multi-task learning or robustness.
3. **Loss Functions**: Dual loss objectives for global and task-specific model refinement.
4. **Color Coding**:
- Green: Homogeneous components.
- Blue: Server-side aggregation.
- Yellow: Heterogeneous components.
- Purple: Projection and Matryoshka representations.
---
### Interpretation
This architecture demonstrates a hybrid federated learning approach:
- **Local Training**: Clients train task-specific models (`g(θ₁)`, `g(θ₂)`, `g(θ₃)`) on their data.
- **Global Aggregation**: Server combines local models into a unified `g(θ)`.
- **Client-Side Personalization**: Matryoshka representations (`Ũ_i`, `Ũ_i^F1`) allow adaptation to individual client data distributions while leveraging global knowledge.
- **Dual Objectives**: Loss 1 optimizes global model accuracy, while Loss 2 ensures task-specific performance via heterogeneous extractors.
The use of Matryoshka Reps implies a focus on hierarchical feature learning, enabling the model to capture both general (global) and client-specific (local) patterns. This design balances personalization and generalization, critical for privacy-preserving federated learning.