\n
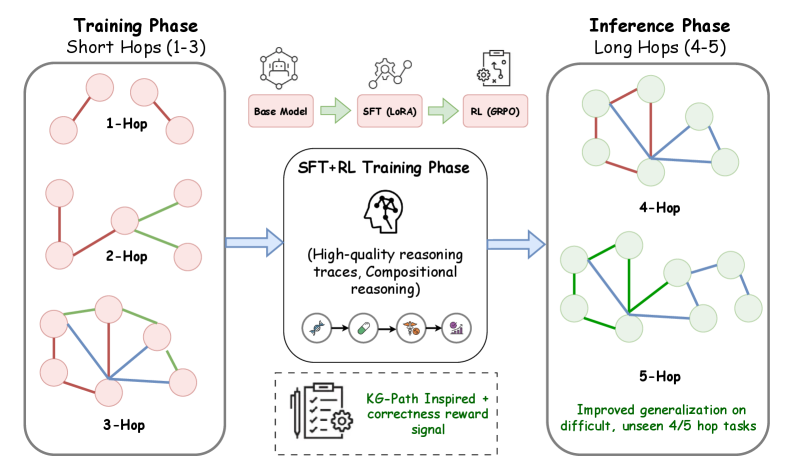
## Diagram: Training and Inference Phases for Reasoning
### Overview
This diagram illustrates a two-phase process: a Training Phase involving short reasoning hops (1-3) and an Inference Phase involving longer reasoning hops (4-5). The diagram depicts the flow of information and the components used in each phase, focusing on the progression from base models to improved generalization through reinforcement learning.
### Components/Axes
The diagram is divided into three main sections: "Training Phase (Short Hops 1-3)", "SFT+RL Training Phase", and "Inference Phase (Long Hops 4-5)". Within each phase, there are visual representations of reasoning hops, depicted as node-link diagrams. The SFT+RL Training Phase section contains icons representing different model components and training techniques.
### Detailed Analysis or Content Details
**Training Phase (Short Hops 1-3):**
* **1-Hop:** A network of 5 nodes connected by 5 edges. The edges are colored green.
* **2-Hop:** A network of 5 nodes connected by 7 edges. The edges are colored red and green.
* **3-Hop:** A network of 5 nodes connected by 9 edges. The edges are colored red and green.
**SFT+RL Training Phase:**
* **Base Model:** Represented by a brain icon.
* **SFT (LoRA):** Represented by a chain-link icon.
* **RL (GRPO):** Represented by a robot icon.
* **Text:** "(High-quality reasoning traces, Compositional reasoning)"
* **KG-Path Inspired + correctness reward signal:** Represented by a gear icon.
**Inference Phase (Long Hops 4-5):**
* **4-Hop:** A network of 5 nodes connected by 9 edges. The edges are colored green and blue.
* **5-Hop:** A network of 5 nodes connected by 11 edges. The edges are colored green and blue.
* **Text:** "Improved generalization on difficult, unseen 4/5 hop tasks"
**Arrows:**
* Blue arrows indicate the flow of information from the Training Phase to the SFT+RL Training Phase, and from the SFT+RL Training Phase to the Inference Phase.
### Key Observations
* The complexity of the reasoning hops increases from the Training Phase to the Inference Phase, as indicated by the increasing number of edges in the node-link diagrams.
* The color of the edges changes from red/green in the Training Phase to green/blue in the Inference Phase, potentially indicating a shift in the type of reasoning or information flow.
* The SFT+RL Training Phase acts as a bridge between the Training and Inference Phases, utilizing different model components to enhance reasoning capabilities.
* The diagram highlights the importance of high-quality reasoning traces and compositional reasoning in the training process.
### Interpretation
The diagram illustrates a methodology for improving reasoning capabilities in a model. The training phase focuses on shorter reasoning chains (1-3 hops) to establish a foundational understanding. This is then enhanced through Supervised Fine-Tuning (SFT) with LoRA and Reinforcement Learning (RL) using GRPO, resulting in high-quality reasoning traces and compositional reasoning. Finally, the model is tested on longer, more complex reasoning chains (4-5 hops) during the inference phase, demonstrating improved generalization on difficult tasks. The change in edge colors between the training and inference phases could signify a change in the type of reasoning being performed, potentially moving from exploratory reasoning (red) to more confident or established reasoning (blue). The use of KG-Path inspired methods and correctness reward signals suggests a focus on grounding the reasoning process in knowledge graphs and ensuring the accuracy of the results. The overall goal is to create a model that can effectively handle complex reasoning tasks by building upon a solid foundation and leveraging advanced training techniques.