## Learning Paradigms: Direct, Reinforcement, and Experiential Learning
### Overview
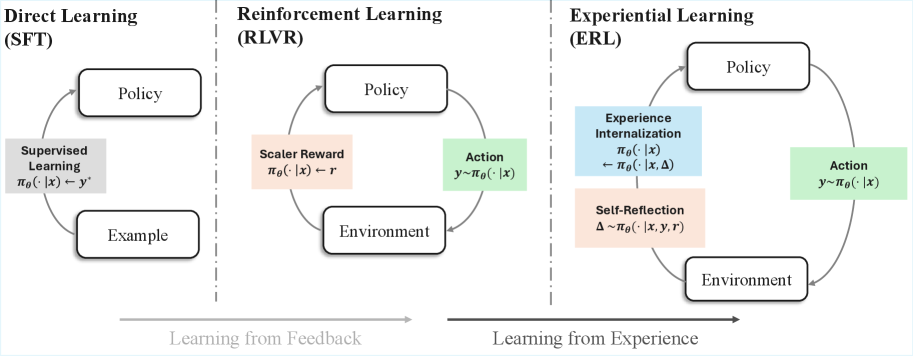
The image presents a comparative diagram illustrating three distinct learning paradigms: Direct Learning (SFT), Reinforcement Learning (RLVR), and Experiential Learning (ERL). Each paradigm is represented by a cyclical flow diagram, highlighting the interaction between different components such as policy, environment, actions, and feedback mechanisms. The diagram emphasizes the shift from learning from explicit examples (Direct Learning) to learning from feedback (Reinforcement Learning) and finally to learning from experience (Experiential Learning).
### Components/Axes
* **Titles:**
* Direct Learning (SFT) - Top-left
* Reinforcement Learning (RLVR) - Top-center
* Experiential Learning (ERL) - Top-right
* **Nodes:** Each paradigm includes nodes representing key components:
* Policy (in all three paradigms)
* Example (Direct Learning)
* Environment (Reinforcement and Experiential Learning)
* Supervised Learning (Direct Learning)
* Scaler Reward (Reinforcement Learning)
* Action (Reinforcement and Experiential Learning)
* Experience Internalization (Experiential Learning)
* Self-Reflection (Experiential Learning)
* **Arrows:** Arrows indicate the flow of information and interaction between the nodes.
* **Equations:** Each node contains equations describing the relationships between variables.
* **Horizontal Axis:** A horizontal axis at the bottom indicates the progression from "Learning from Feedback" to "Learning from Experience."
### Detailed Analysis or ### Content Details
**1. Direct Learning (SFT):**
* **Policy:** Located at the top.
* **Example:** Located at the bottom.
* **Supervised Learning:** Located on the left side, between Policy and Example.
* Equation: πθ(· | x) → y'
* **Flow:** The flow starts from the Example, goes to Supervised Learning, then to Policy, and back to Example, forming a loop.
**2. Reinforcement Learning (RLVR):**
* **Policy:** Located at the top.
* **Environment:** Located at the bottom.
* **Action:** Located on the right side, between Policy and Environment.
* Equation: y ~ πθ(· | x)
* **Scaler Reward:** Located on the left side, between Policy and Environment.
* Equation: πθ(· | x) → r
* **Flow:** The flow starts from the Environment, goes to Scaler Reward, then to Policy, then to Action, and back to Environment, forming a loop.
**3. Experiential Learning (ERL):**
* **Policy:** Located at the top.
* **Environment:** Located at the bottom.
* **Action:** Located on the right side, between Policy and Environment.
* Equation: y ~ πθ(· | x)
* **Experience Internalization:** Located on the left side, above Self-Reflection, between Policy and Environment.
* Equation: πθ(· | x) ← πθ(· | x, Δ)
* **Self-Reflection:** Located on the left side, below Experience Internalization, between Policy and Environment.
* Equation: Δ ~ πθ(· | x, y, r)
* **Flow:** The flow starts from the Environment, goes to Self-Reflection, then to Experience Internalization, then to Policy, then to Action, and back to Environment, forming a loop.
### Key Observations
* **Progression:** The diagrams illustrate a progression from simple supervised learning to more complex reinforcement and experiential learning.
* **Feedback:** Reinforcement Learning introduces the concept of a scalar reward, while Experiential Learning incorporates experience internalization and self-reflection.
* **Complexity:** Experiential Learning has the most complex flow, involving multiple feedback loops and internal processes.
### Interpretation
The image effectively visualizes the evolution of learning paradigms. Direct Learning relies on explicit examples, Reinforcement Learning learns from feedback signals (rewards), and Experiential Learning learns by internalizing experiences and reflecting on them. The diagrams highlight the increasing complexity and sophistication of learning algorithms as they move from supervised to reinforcement and experiential learning. The inclusion of equations within each node provides a concise mathematical representation of the relationships between the components. The progression from "Learning from Feedback" to "Learning from Experience" suggests a shift towards more autonomous and adaptive learning systems.