\n
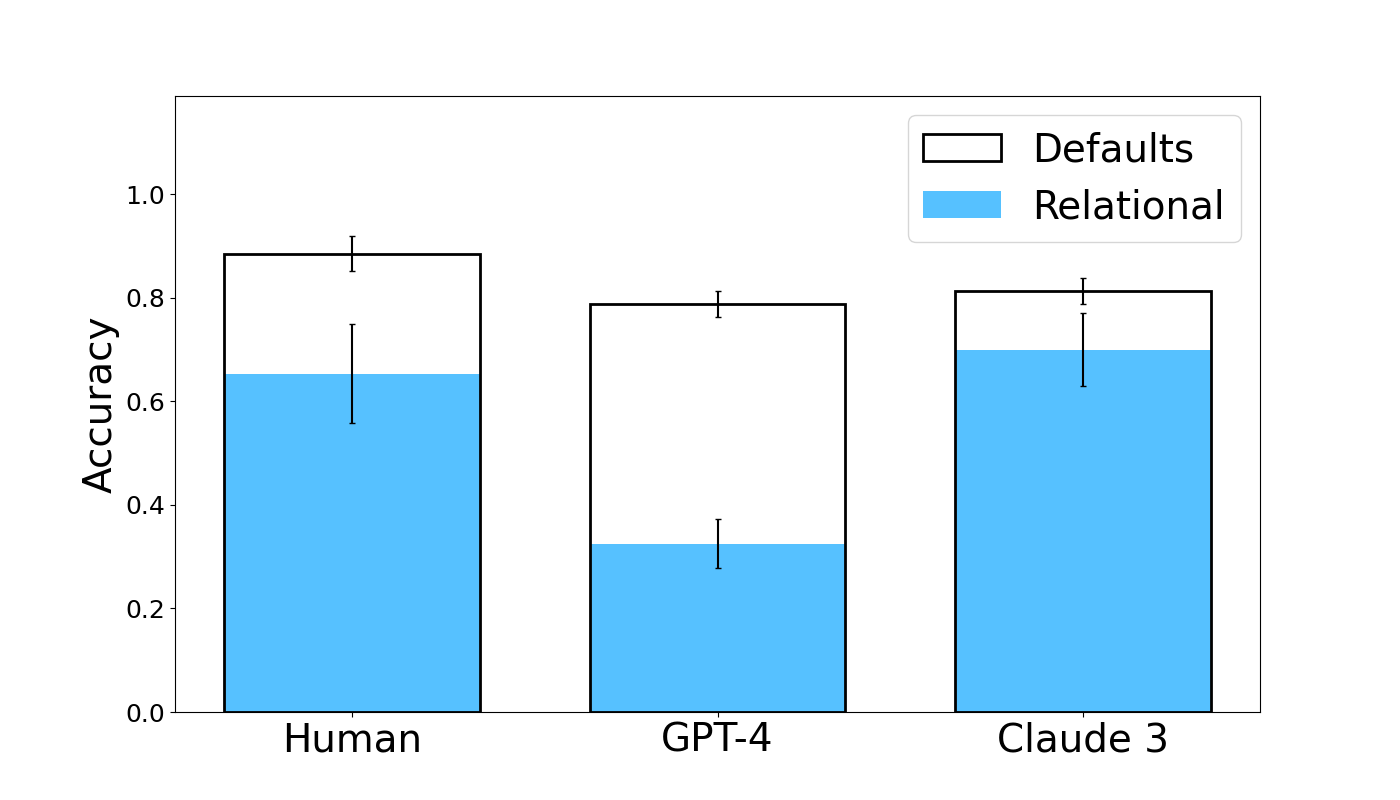
## Bar Chart: Accuracy Comparison - Human, GPT-4, and Claude 3
### Overview
This bar chart compares the accuracy of three entities – Human, GPT-4, and Claude 3 – under two conditions: "Defaults" and "Relational". Accuracy is represented on the y-axis, and the entities are displayed on the x-axis. Each bar represents the average accuracy, with error bars indicating the variability or confidence interval around that average.
### Components/Axes
* **X-axis:** Entity - with categories: Human, GPT-4, Claude 3.
* **Y-axis:** Accuracy - Scale ranges from 0.0 to 1.0.
* **Legend:**
* "Defaults" - Represented by a black outline and white fill.
* "Relational" - Represented by a light blue fill.
### Detailed Analysis
The chart consists of three groups of bars, one for each entity (Human, GPT-4, Claude 3). Each group contains two bars: one for "Defaults" and one for "Relational". Error bars are present on top of each bar, indicating the standard deviation or confidence interval.
* **Human:**
* "Defaults": Approximately 0.85 accuracy, with an error bar extending from roughly 0.75 to 0.95.
* "Relational": Approximately 0.68 accuracy, with an error bar extending from roughly 0.55 to 0.80.
* **GPT-4:**
* "Defaults": Approximately 0.78 accuracy, with an error bar extending from roughly 0.68 to 0.88.
* "Relational": Approximately 0.34 accuracy, with an error bar extending from roughly 0.20 to 0.48.
* **Claude 3:**
* "Defaults": Approximately 0.73 accuracy, with an error bar extending from roughly 0.63 to 0.83.
* "Relational": Approximately 0.66 accuracy, with an error bar extending from roughly 0.55 to 0.77.
### Key Observations
* Humans achieve the highest accuracy in both "Defaults" and "Relational" conditions.
* GPT-4 shows a significant drop in accuracy when switching from "Defaults" to "Relational".
* Claude 3 maintains a relatively consistent accuracy across both conditions, though lower than Human "Defaults".
* The error bars suggest that the accuracy of "Defaults" is more consistent than "Relational" for all three entities.
### Interpretation
The data suggests that all three entities perform better under "Defaults" conditions. The substantial decrease in GPT-4's accuracy when using "Relational" indicates that it struggles with tasks requiring relational reasoning or understanding of relationships between entities. Humans consistently outperform the models, particularly in the "Relational" condition, highlighting the current limitations of AI in complex reasoning tasks. Claude 3 demonstrates a more robust performance in the "Relational" condition compared to GPT-4, suggesting a potentially better ability to handle relational data. The error bars indicate that the variability in performance is higher for the "Relational" condition, suggesting that these tasks are more sensitive to variations in input or model parameters. This chart likely represents the results of a benchmark test designed to evaluate the performance of different entities on tasks requiring varying levels of reasoning complexity.