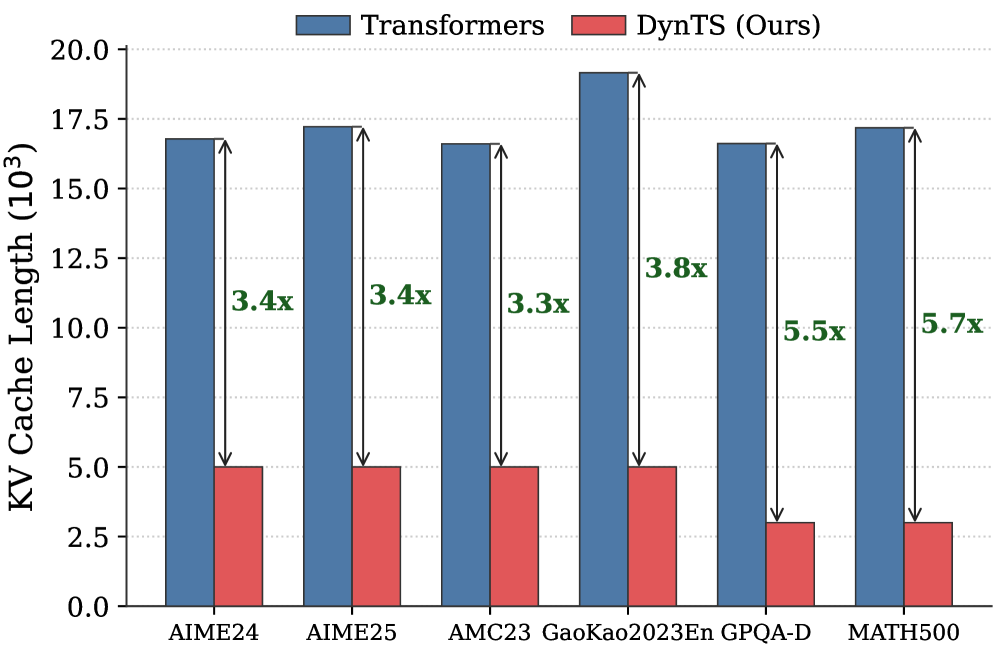
## Bar Chart: KV Cache Length Comparison
### Overview
The image is a bar chart comparing the KV Cache Length (in thousands) of "Transformers" and "DynTS (Ours)" across six different datasets: AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, and MATH500. The chart displays the cache length for each model on each dataset, along with the multiplicative factor showing how much smaller DynTS is compared to Transformers.
### Components/Axes
* **Title:** KV Cache Length (103)
* **X-axis:** Datasets (AIME24, AIME25, AMC23, GaoKao2023En, GPQA-D, MATH500)
* **Y-axis:** KV Cache Length (103), ranging from 0.0 to 20.0 with increments of 2.5.
* **Legend:** Located at the top of the chart.
* Blue: Transformers
* Red: DynTS (Ours)
### Detailed Analysis
Here's a breakdown of the KV Cache Length for each dataset and model:
* **AIME24:**
* Transformers (Blue): Approximately 17.0 x 10^3
* DynTS (Ours) (Red): Approximately 5.0 x 10^3
* Factor: 3.4x
* **AIME25:**
* Transformers (Blue): Approximately 17.3 x 10^3
* DynTS (Ours) (Red): Approximately 5.1 x 10^3
* Factor: 3.4x
* **AMC23:**
* Transformers (Blue): Approximately 16.7 x 10^3
* DynTS (Ours) (Red): Approximately 5.0 x 10^3
* Factor: 3.3x
* **GaoKao2023En:**
* Transformers (Blue): Approximately 19.2 x 10^3
* DynTS (Ours) (Red): Approximately 5.0 x 10^3
* Factor: 3.8x
* **GPQA-D:**
* Transformers (Blue): Approximately 16.7 x 10^3
* DynTS (Ours) (Red): Approximately 3.0 x 10^3
* Factor: 5.5x
* **MATH500:**
* Transformers (Blue): Approximately 17.3 x 10^3
* DynTS (Ours) (Red): Approximately 3.0 x 10^3
* Factor: 5.7x
### Key Observations
* Transformers consistently have a higher KV Cache Length than DynTS across all datasets.
* The multiplicative factor (showing how much smaller DynTS is) varies from 3.3x to 5.7x.
* DynTS shows the most significant reduction in KV Cache Length compared to Transformers on the MATH500 and GPQA-D datasets.
* Transformers' KV Cache Length is relatively consistent across all datasets, ranging from approximately 16.7 x 10^3 to 19.2 x 10^3.
### Interpretation
The bar chart demonstrates that DynTS (Ours) significantly reduces the KV Cache Length compared to the standard Transformers model across various datasets. The reduction factor ranges from 3.3x to 5.7x, indicating a substantial improvement in memory efficiency. This suggests that DynTS is a more memory-efficient alternative to Transformers, particularly for the MATH500 and GPQA-D datasets. The consistent KV Cache Length of Transformers across datasets suggests a relatively fixed memory footprint, while DynTS adapts more effectively to different dataset characteristics.