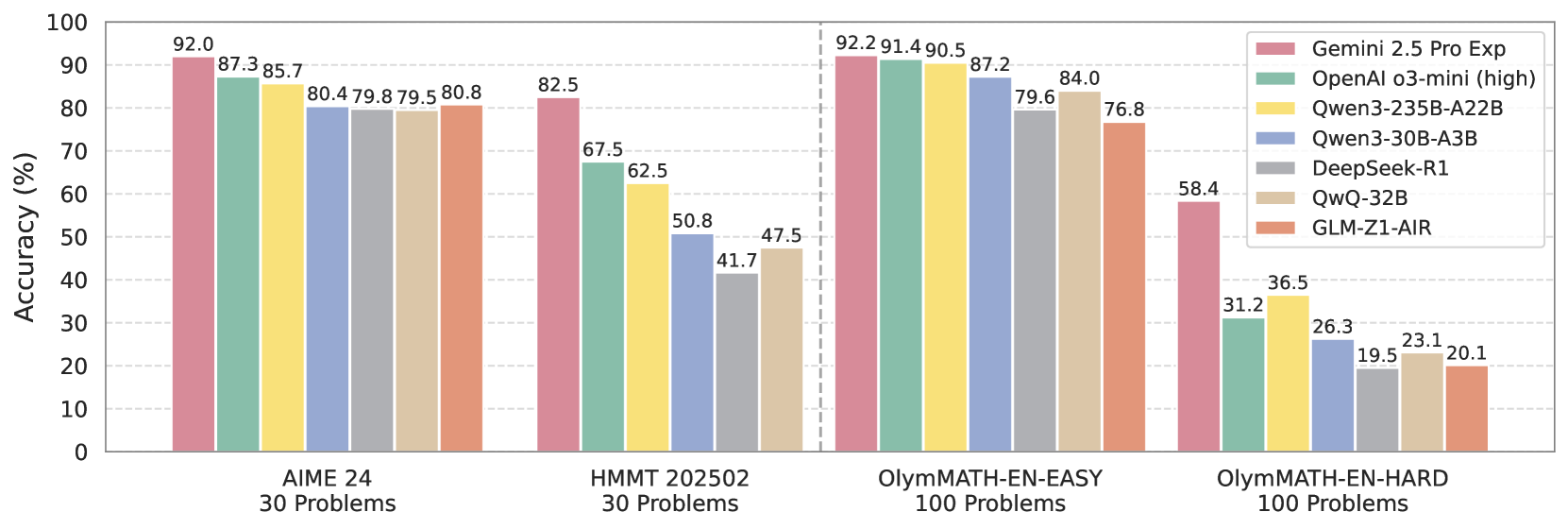
## Bar Chart: Accuracy Comparison of Different Models on Math Problems
### Overview
The image is a bar chart comparing the accuracy (in percentage) of seven different models on four different math problem sets: AIME 24, HMMT 202502, OlymMATH-EN-EASY, and OlymMATH-EN-HARD. Each problem set has a specified number of problems. The models being compared are Gemini 2.5 Pro Exp, OpenAI o3-mini (high), Qwen3-235B-A22B, Qwen3-30B-A3B, DeepSeek-R1, QwQ-32B, and GLM-Z1-AIR.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0 to 100. Increments of 10 are marked.
* **X-axis:** Four categories representing different math problem sets:
* AIME 24 (30 Problems)
* HMMT 202502 (30 Problems)
* OlymMATH-EN-EASY (100 Problems)
* OlymMATH-EN-HARD (100 Problems)
* **Legend:** Located on the top-right of the chart, mapping model names to bar colors:
* Gemini 2.5 Pro Exp (Pale Pink)
* OpenAI o3-mini (high) (Pale Green)
* Qwen3-235B-A22B (Yellow)
* Qwen3-30B-A3B (Light Blue)
* DeepSeek-R1 (Gray)
* QwQ-32B (Pale Beige)
* GLM-Z1-AIR (Light Orange)
### Detailed Analysis
**AIME 24 (30 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 92.0%
* OpenAI o3-mini (high) (Pale Green): 87.3%
* Qwen3-235B-A22B (Yellow): 85.7%
* Qwen3-30B-A3B (Light Blue): 80.4%
* DeepSeek-R1 (Gray): 79.8%
* QwQ-32B (Pale Beige): 79.5%
* GLM-Z1-AIR (Light Orange): 80.8%
**HMMT 202502 (30 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 82.5%
* OpenAI o3-mini (high) (Pale Green): 67.5%
* Qwen3-235B-A22B (Yellow): 62.5%
* Qwen3-30B-A3B (Light Blue): 50.8%
* DeepSeek-R1 (Gray): 41.7%
* QwQ-32B (Pale Beige): 47.5%
* GLM-Z1-AIR (Light Orange): Not specified, but visually estimated to be around 47.5%
**OlymMATH-EN-EASY (100 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 92.2%
* OpenAI o3-mini (high) (Pale Green): 91.4%
* Qwen3-235B-A22B (Yellow): 90.5%
* Qwen3-30B-A3B (Light Blue): 87.2%
* DeepSeek-R1 (Gray): 79.6%
* QwQ-32B (Pale Beige): 84.0%
* GLM-Z1-AIR (Light Orange): 76.8%
**OlymMATH-EN-HARD (100 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 58.4%
* OpenAI o3-mini (high) (Pale Green): 31.2%
* Qwen3-235B-A22B (Yellow): 36.5%
* Qwen3-30B-A3B (Light Blue): 26.3%
* DeepSeek-R1 (Gray): 19.5%
* QwQ-32B (Pale Beige): 23.1%
* GLM-Z1-AIR (Light Orange): 20.1%
### Key Observations
* Gemini 2.5 Pro Exp consistently performs well across all problem sets, achieving the highest accuracy in three out of the four categories.
* The accuracy of all models decreases significantly on the OlymMATH-EN-HARD problem set, indicating its higher difficulty level.
* OpenAI o3-mini (high) shows strong performance on OlymMATH-EN-EASY, closely following Gemini 2.5 Pro Exp.
* DeepSeek-R1 and GLM-Z1-AIR generally have lower accuracy compared to the other models, especially on the harder problem sets.
### Interpretation
The bar chart provides a comparative analysis of the accuracy of different language models on various math problem sets. The data suggests that Gemini 2.5 Pro Exp is a strong performer across different difficulty levels, while other models like OpenAI o3-mini (high) also exhibit competitive performance on specific problem sets. The significant drop in accuracy on the OlymMATH-EN-HARD problem set highlights the challenges associated with solving more complex mathematical problems. The chart is useful for understanding the relative strengths and weaknesses of each model in the context of mathematical reasoning and problem-solving.