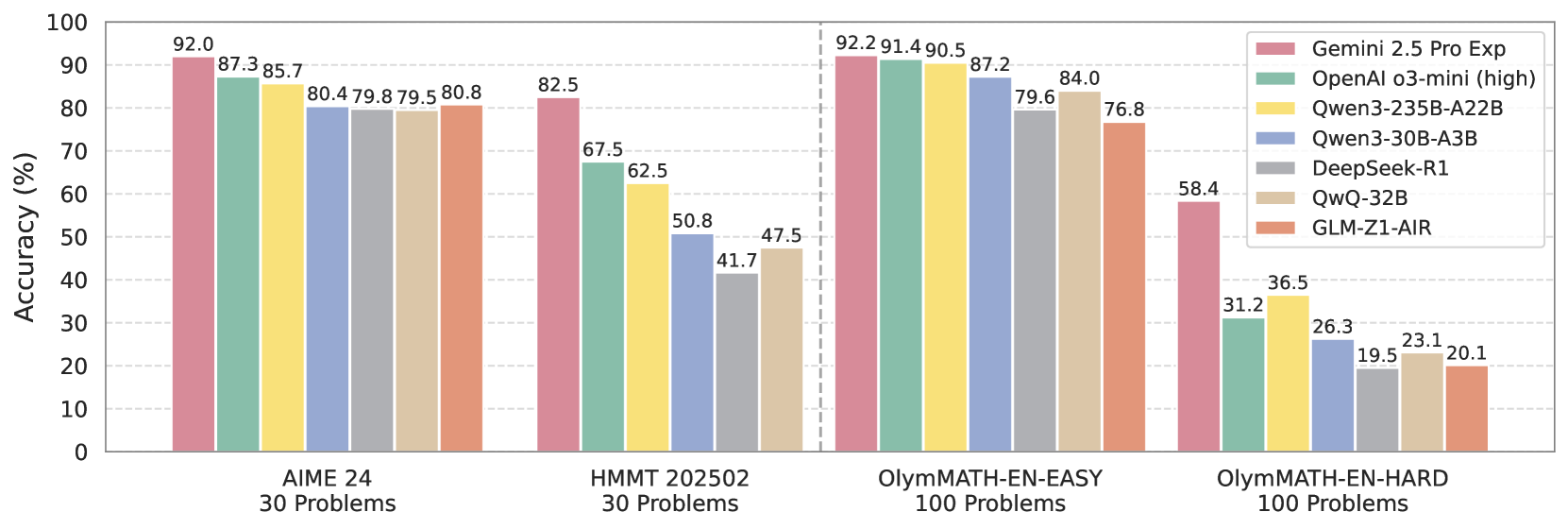
## Bar Chart: Model Accuracy on Math Problems
### Overview
This bar chart compares the accuracy of several large language models (LLMs) on four different math problem sets: AIME 24 (30 problems), HMMT 202502 (30 problems), OlyMATH-EN-EASY (100 problems), and OlyMATH-EN-HARD (100 problems). Accuracy is measured as a percentage.
### Components/Axes
* **X-axis:** Represents the math problem sets: AIME 24, HMMT 202502, OlyMATH-EN-EASY, and OlyMATH-EN-HARD.
* **Y-axis:** Represents Accuracy (%), ranging from 0 to 100.
* **Legend (Top-Right):** Identifies the different LLMs being compared, with corresponding colors:
* Gemini 2.5 Pro Exp (Reddish-Brown)
* OpenAI o3-mini (high) (Blue)
* Qwen3-235B-A22B (Yellow)
* Qwen3-30B-A3B (Green)
* DeepSeek-R1 (Teal)
* QwQ-32B (Orange)
* GLM-Z1-AIR (Light-Brown)
### Detailed Analysis
The chart consists of four groups of bars, one for each problem set. Within each group, there is a bar for each LLM.
**AIME 24 (30 Problems):**
* Gemini 2.5 Pro Exp: Approximately 92.0%
* OpenAI o3-mini (high): Approximately 87.3%
* Qwen3-235B-A22B: Approximately 85.7%
* Qwen3-30B-A3B: Approximately 80.4%
**HMMT 202502 (30 Problems):**
* Gemini 2.5 Pro Exp: Approximately 82.5%
* OpenAI o3-mini (high): Approximately 67.5%
* Qwen3-235B-A22B: Approximately 62.5%
* Qwen3-30B-A3B: Approximately 50.8%
* DeepSeek-R1: Approximately 47.5%
**OlyMATH-EN-EASY (100 Problems):**
* Gemini 2.5 Pro Exp: Approximately 92.2%
* OpenAI o3-mini (high): Approximately 91.4%
* Qwen3-235B-A22B: Approximately 90.5%
* Qwen3-30B-A3B: Approximately 87.2%
**OlyMATH-EN-HARD (100 Problems):**
* Gemini 2.5 Pro Exp: Approximately 58.4%
* OpenAI o3-mini (high): Approximately 36.5%
* Qwen3-235B-A22B: Approximately 31.2%
* Qwen3-30B-A3B: Approximately 26.3%
* DeepSeek-R1: Approximately 23.1%
* QwQ-32B: Approximately 19.5%
* GLM-Z1-AIR: Approximately 20.1%
### Key Observations
* Gemini 2.5 Pro Exp consistently achieves the highest accuracy across all problem sets.
* Accuracy generally decreases as the difficulty of the problem set increases (from AIME 24 to OlyMATH-EN-HARD).
* The performance gap between the models is most pronounced on the OlyMATH-EN-HARD dataset.
* OpenAI o3-mini (high) performs well on AIME 24 and OlyMATH-EN-EASY, but its performance drops significantly on the harder datasets.
* GLM-Z1-AIR consistently shows the lowest performance among the models tested.
### Interpretation
The data suggests that Gemini 2.5 Pro Exp is the most capable LLM for solving these math problems, demonstrating a robust ability to handle varying levels of difficulty. The decline in accuracy across all models as the problem sets become harder indicates that even advanced LLMs struggle with complex mathematical reasoning. The significant performance difference on the OlyMATH-EN-HARD dataset highlights the challenges of solving difficult problems and the potential for further improvement in LLM capabilities. The consistent lower performance of GLM-Z1-AIR suggests it may require further development to achieve comparable accuracy to other models. The chart provides a comparative benchmark of LLM performance on different math problem sets, which can be valuable for researchers and developers working on improving LLM capabilities in mathematical reasoning.