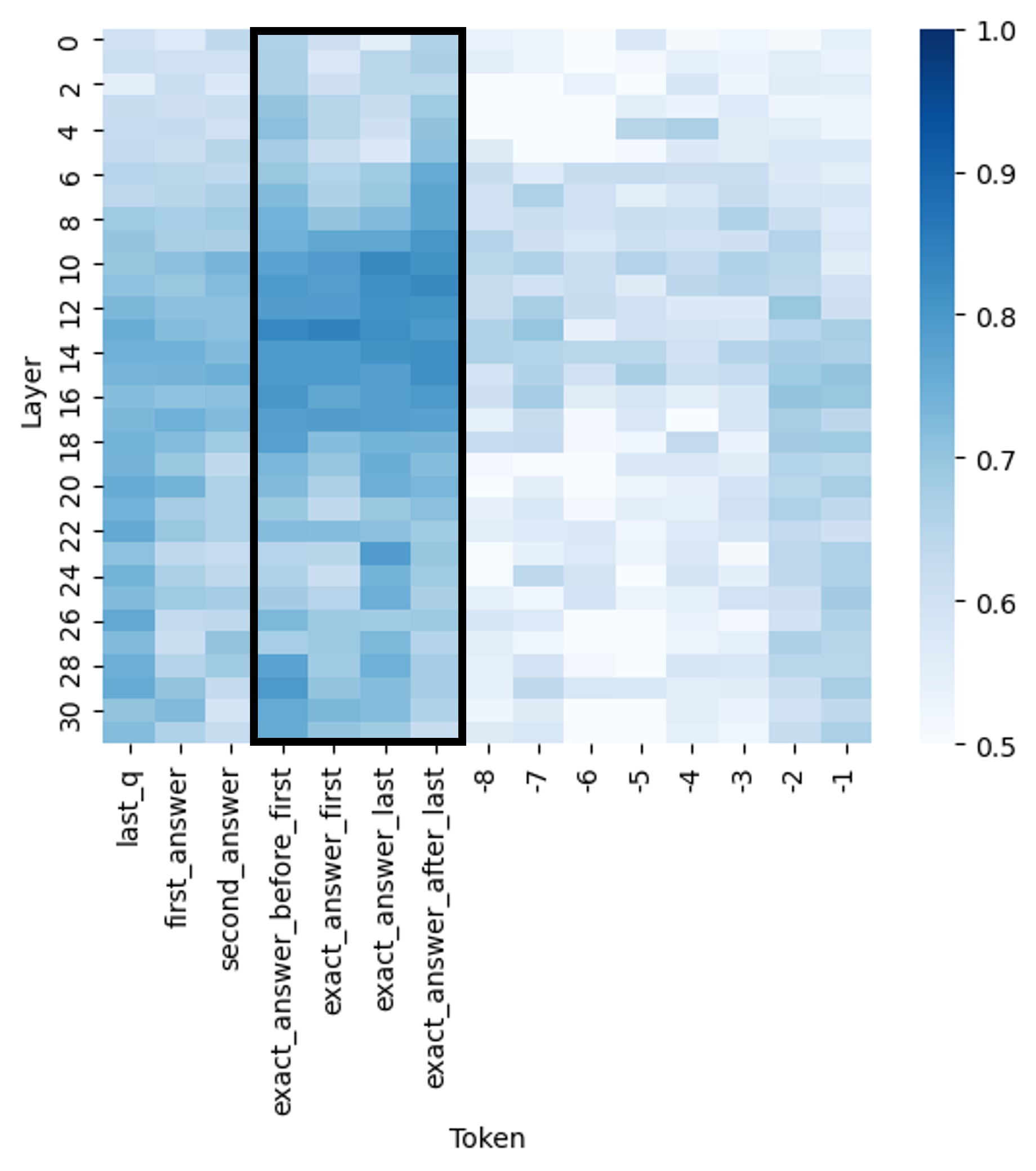
## Heatmap: Layer vs. Token Activation/Attention
### Overview
The image displays a heatmap visualizing a numerical value (likely attention weight, activation strength, or correlation) across two dimensions: **Layer** (vertical axis) and **Token** (horizontal axis). The data is represented by a color gradient from light blue (low value) to dark blue (high value). A prominent black rectangular outline highlights a specific region of interest within the heatmap.
### Components/Axes
* **Y-Axis (Vertical):** Labeled **"Layer"**. The scale runs from **0** at the top to **30** at the bottom, with major tick marks at every even number (0, 2, 4, ..., 30). This likely represents layers in a neural network model.
* **X-Axis (Horizontal):** Labeled **"Token"**. It contains a series of categorical and numerical labels. From left to right, the labels are:
* `last_q`
* `first_answer`
* `second_answer`
* `exact_answer_before_first`
* `exact_answer_first`
* `exact_answer_last`
* `exact_answer_after_last`
* `-8`
* `-7`
* `-6`
* `-5`
* `-4`
* `-3`
* `-2`
* `-1`
* **Color Scale/Legend:** Positioned on the right side of the chart. It is a vertical color bar labeled with numerical values. The scale ranges from **0.5** (lightest blue/white at the bottom) to **1.0** (darkest blue at the top), with intermediate markers at **0.6, 0.7, 0.8, and 0.9**.
* **Highlighted Region:** A thick black rectangle is drawn around a vertical block of cells. This region spans horizontally from the token `exact_answer_before_first` to `exact_answer_after_last` (covering four token columns) and vertically across all layers (0 to 30).
### Detailed Analysis
The heatmap shows a grid of colored cells, where each cell's color corresponds to a value between approximately 0.5 and 1.0.
* **General Pattern:** The left side of the heatmap (tokens `last_q` through `exact_answer_after_last`) generally exhibits higher values (darker blue shades) compared to the right side (numerical tokens `-8` to `-1`), which are predominantly lighter.
* **Within the Highlighted Region:** The four columns within the black rectangle (`exact_answer_before_first`, `exact_answer_first`, `exact_answer_last`, `exact_answer_after_last`) show the highest concentration of dark blue cells, indicating values consistently in the upper range of the scale (0.7 to 1.0). The intensity appears particularly strong in the middle layers (approximately layers 8 through 20).
* **Layer Trends:** For the highlighted tokens, values seem to peak in the middle layers and are slightly lower in the very top (0-4) and bottom (26-30) layers. For the numerical tokens on the right, values are uniformly low across all layers, with only faint blue shading.
* **Token Trends:** Moving from left to right across the x-axis, there is a clear gradient of decreasing value intensity. The `exact_answer_*` tokens have the highest values, followed by `second_answer` and `first_answer`, then `last_q`. The numerical tokens (`-8` to `-1`) have the lowest values.
### Key Observations
1. **Strongest Signal:** The model's layers show the strongest response (highest values) to tokens related to the "exact answer" (`exact_answer_before_first`, `exact_answer_first`, `exact_answer_last`, `exact_answer_after_last`).
2. **Spatial Focus:** The black rectangle explicitly draws attention to this "exact answer" token group, suggesting it is the primary subject of analysis.
3. **Clear Dichotomy:** There is a stark contrast between the high-value region on the left (semantic/answer tokens) and the low-value region on the right (numerical position tokens).
4. **Mid-Layer Peak:** Within the high-value region, the signal is not uniform across layers; it appears most intense in the network's middle layers.
### Interpretation
This heatmap likely visualizes **attention weights** or **activation patterns** in a transformer-based language model during a question-answering task. The data suggests the following:
* **Model Focus:** The model allocates significantly more "attention" or computational resources to tokens directly surrounding and comprising the exact answer compared to other parts of the input (like the question token `last_q` or positional markers `-8` to `-1`).
* **Information Processing:** The concentration of high values in the middle layers aligns with common findings in neural network interpretability, where mid-level layers often process task-specific, semantic information.
* **Functional Implication:** The pattern indicates the model has learned to identify and prioritize the span of text that constitutes the precise answer. The tokens `exact_answer_before_first` and `exact_answer_after_last` likely act as boundary markers, helping the model isolate the answer span. The low values for numerical tokens suggest they serve a minor, possibly structural, role that does not require strong activation.
* **Anomaly/Outlier:** There are no major outliers; the gradient from high to low values across token types is smooth and consistent, indicating a robust and focused pattern of model behavior for this task. The black rectangle is an annotation, not a data feature, used to emphasize the key finding.