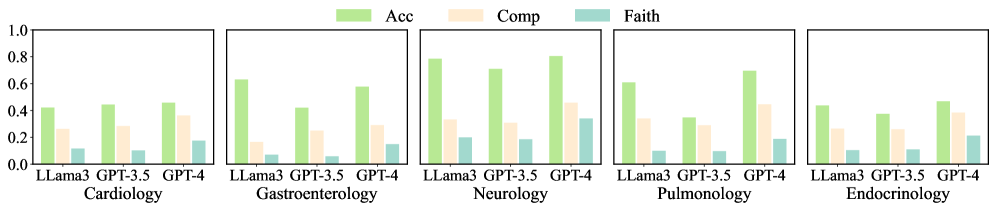
## Grouped Bar Chart: Model Performance Across Medical Specialties
### Overview
The image displays a series of five grouped bar charts, each representing a different medical specialty. The charts compare the performance of three large language models (LLaMA3, GPT-3.5, GPT-4) across three evaluation metrics: Accuracy (Acc), Completeness (Comp), and Faithfulness (Faith). The overall layout is a single row of five subplots, each with its own title.
### Components/Axes
* **Legend:** Located at the top center of the entire figure. It defines three metrics with corresponding colors:
* **Acc (Accuracy):** Light green bar.
* **Comp (Completeness):** Light beige/peach bar.
* **Faith (Faithfulness):** Light teal/blue-green bar.
* **Y-Axis:** Common to all subplots, labeled from `0.0` to `1.0` in increments of `0.2`. This represents the score for each metric.
* **X-Axis (per subplot):** Lists the three models being compared: `LLaMA3`, `GPT-3.5`, `GPT-4`.
* **Subplot Titles:** Each of the five charts is titled with a medical specialty, positioned below its respective x-axis:
1. Cardiology
2. Gastroenterology
3. Neurology
4. Pulmonology
5. Endocrinology
### Detailed Analysis
Below are the approximate values extracted from each bar chart. Values are estimated based on the y-axis scale.
**1. Cardiology**
| Model | Accuracy (Acc) | Completeness (Comp) | Faithfulness (Faith) |
| :------ | :------------- | :------------------ | :------------------- |
| LLaMA3 | ≈ 0.42 | ≈ 0.28 | ≈ 0.12 |
| GPT-3.5 | ≈ 0.45 | ≈ 0.30 | ≈ 0.10 |
| GPT-4 | ≈ 0.48 | ≈ 0.38 | ≈ 0.18 |
* **Trend:** All metrics show a gradual increase from LLaMA3 to GPT-4. Faithfulness is notably the lowest metric for all models.
**2. Gastroenterology**
| Model | Accuracy (Acc) | Completeness (Comp) | Faithfulness (Faith) |
| :------ | :------------- | :------------------ | :------------------- |
| LLaMA3 | ≈ 0.65 | ≈ 0.18 | ≈ 0.08 |
| GPT-3.5 | ≈ 0.42 | ≈ 0.25 | ≈ 0.06 |
| GPT-4 | ≈ 0.58 | ≈ 0.30 | ≈ 0.15 |
* **Trend:** LLaMA3 has the highest Accuracy but the lowest Completeness and Faithfulness. GPT-4 shows balanced improvement over GPT-3.5.
**3. Neurology**
| Model | Accuracy (Acc) | Completeness (Comp) | Faithfulness (Faith) |
| :------ | :------------- | :------------------ | :------------------- |
| LLaMA3 | ≈ 0.78 | ≈ 0.35 | ≈ 0.20 |
| GPT-3.5 | ≈ 0.72 | ≈ 0.32 | ≈ 0.18 |
| GPT-4 | ≈ 0.82 | ≈ 0.45 | ≈ 0.35 |
* **Trend:** This specialty shows the highest overall scores. GPT-4 leads significantly in all metrics, with a particularly strong jump in Faithfulness.
**4. Pulmonology**
| Model | Accuracy (Acc) | Completeness (Comp) | Faithfulness (Faith) |
| :------ | :------------- | :------------------ | :------------------- |
| LLaMA3 | ≈ 0.62 | ≈ 0.35 | ≈ 0.10 |
| GPT-3.5 | ≈ 0.35 | ≈ 0.30 | ≈ 0.10 |
| GPT-4 | ≈ 0.70 | ≈ 0.45 | ≈ 0.18 |
* **Trend:** GPT-3.5 shows a significant dip in Accuracy compared to the other models. GPT-4 again demonstrates the strongest performance.
**5. Endocrinology**
| Model | Accuracy (Acc) | Completeness (Comp) | Faithfulness (Faith) |
| :------ | :------------- | :------------------ | :------------------- |
| LLaMA3 | ≈ 0.45 | ≈ 0.28 | ≈ 0.08 |
| GPT-3.5 | ≈ 0.38 | ≈ 0.25 | ≈ 0.10 |
| GPT-4 | ≈ 0.48 | ≈ 0.40 | ≈ 0.20 |
* **Trend:** Performance is relatively lower and more uniform across models compared to other specialties, though GPT-4 still leads.
### Key Observations
1. **Model Hierarchy:** GPT-4 consistently achieves the highest scores across nearly all specialties and metrics, followed generally by LLaMA3, with GPT-3.5 often performing the worst.
2. **Metric Disparity:** **Faithfulness (Faith)** is consistently the lowest-scoring metric for every model in every specialty, often by a significant margin. **Accuracy (Acc)** is typically the highest-scoring metric.
3. **Specialty Variance:** **Neurology** yields the highest performance scores for all models. **Gastroenterology** and **Pulmonology** show the most volatile performance, with models like LLaMA3 and GPT-3.5 exhibiting sharp drops in specific metrics.
4. **GPT-3.5 Anomaly:** In Pulmonology, GPT-3.5's Accuracy score drops to approximately 0.35, which is notably lower than its performance in other specialties and lower than both LLaMA3 and GPT-4 in the same category.
### Interpretation
The data suggests a clear performance advantage for the GPT-4 model in the context of these medical specialty evaluations. Its lead is most pronounced in the **Faithfulness** metric, which may indicate superior reliability or grounding in factual information compared to the other models.
The consistently low **Faithfulness** scores across all models and specialties highlight a potential systemic challenge for LLMs in medical domains: generating responses that are not only accurate and complete but also faithfully adhere to source material or established medical knowledge without hallucination.
The variation in performance across specialties (e.g., high scores in Neurology vs. lower scores in Endocrinology) implies that model capability is not uniform. This could be due to differences in the volume or quality of training data available for each medical field, or the inherent complexity and specificity of the questions within each domain. The poor performance of GPT-3.5 in Pulmonology's Accuracy metric is a notable outlier that would warrant further investigation into the specific test cases for that category.