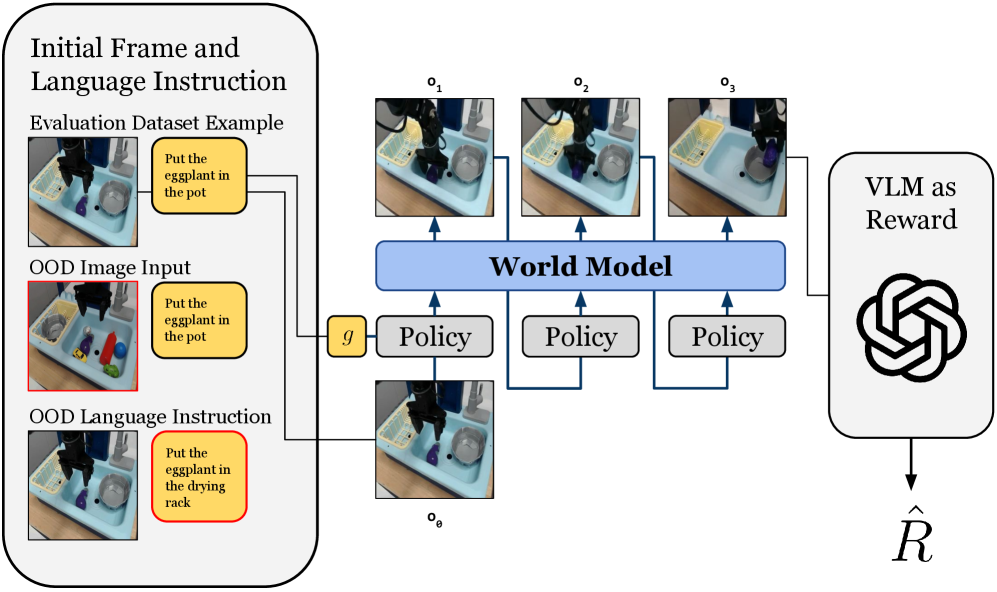
## Diagram: Robot Task Execution System with World Model and VLM Reward
### Overview
This diagram illustrates a robotic task execution system that integrates a world model, policy execution, and vision-language model (VLM) reward evaluation. The system processes initial frames, language instructions, and out-of-distribution (OOD) inputs to generate and evaluate robotic actions.
### Components/Axes
1. **Left Panel: Initial Inputs**
- **Initial Frame and Language Instruction**: Contains two scenarios:
- *Evaluation Dataset Example*: "Put the eggplant in the pot" (correct instruction)
- *OOD Image Input*: Modified image with additional objects (red border)
- *OOD Language Instruction*: Modified instruction "Put the eggplant in the drying rack" (red border)
- **Key Elements**: Robot arm, sink environment, objects (eggplant, pot, drying rack)
2. **Central Panel: World Model and Policies**
- **World Model**: Central processing unit receiving sequential observations (o₁, o₂, o₃)
- **Policy Blocks**: Three identical policy modules processing observations (o₁→o₃) and outputting actions (oθ)
- **Flow**: Observations feed into world model → policies → world model (recurrent loop)
3. **Right Panel: VLM Reward**
- **VLM as Reward**: Hexagonal symbol representing vision-language model
- **Output**: Reward value (R̂) derived from policy evaluation
### Detailed Analysis
- **Initial Inputs**:
- Correct instruction: "Put the eggplant in the pot" (yellow box)
- OOD variations:
- Image: Additional objects (red border)
- Language: "Put the eggplant in the drying rack" (red border)
- **World Model**:
- Processes sequential observations (o₁→o₃) showing robot arm movement
- Maintains internal state (g) representing environment dynamics
- **Policy Execution**:
- Three identical policy modules process different observation states
- Outputs action sequences (oθ) for robotic execution
- **VLM Reward System**:
- Evaluates policy outputs using vision-language model
- Generates scalar reward (R̂) for action quality assessment
### Key Observations
1. **OOD Handling**: Red borders highlight system's ability to process instruction/image mismatches
2. **Recurrent Architecture**: World model maintains state between policy executions
3. **Modular Design**: Separate policy blocks suggest parallel processing capability
4. **Reward Integration**: VLM directly influences policy evaluation without explicit training signals
### Interpretation
This system demonstrates a closed-loop robotic control architecture where:
1. **World Model** serves as both environment simulator and memory
2. **Policies** generate actions based on current observations and historical context
3. **VLM Reward** provides real-time evaluation of action quality through vision-language understanding
4. **OOD Robustness**: The system explicitly handles instruction-image mismatches through separate OOD input channels
The architecture suggests a hierarchical approach where:
- Low-level policies execute basic actions
- World model maintains high-level context
- VLM provides semantic evaluation of action-instruction alignment
- Recurrent connections enable continuous learning from execution outcomes
The use of identical policy blocks implies transfer learning capabilities across different observation states, while the VLM reward system enables value-based policy selection without explicit reward shaping.