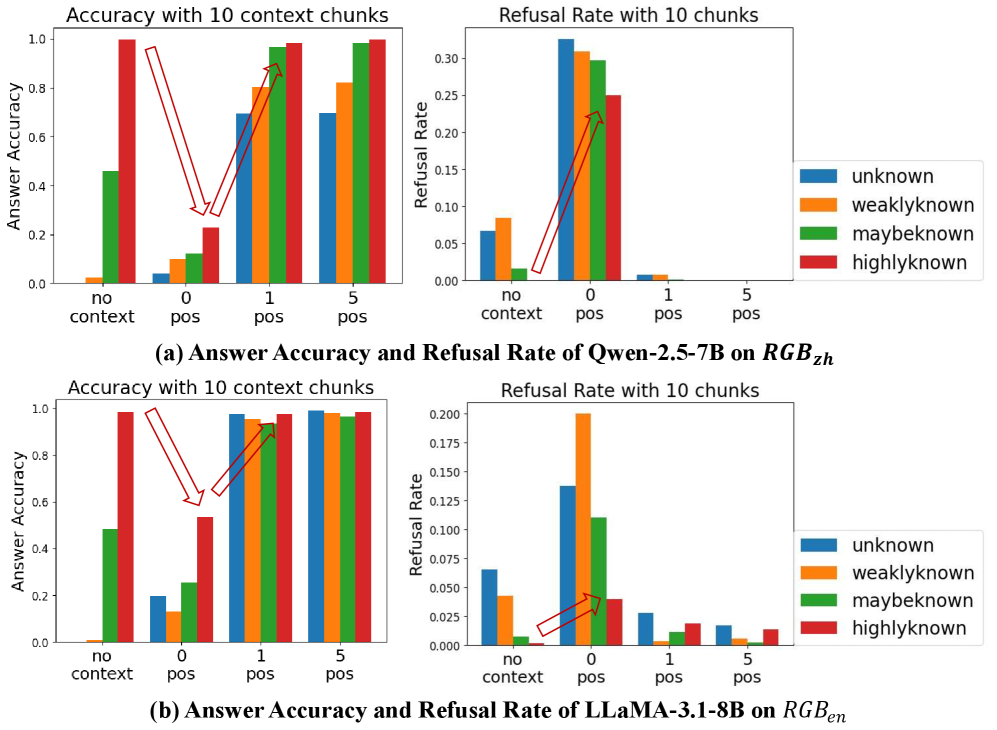
## Bar Charts: Answer Accuracy and Refusal Rate of Qwen-2.5-7B and LLaMA-3.1-8B on RGB Datasets
### Overview
The image contains four grouped bar charts comparing the performance of two language models (Qwen-2.5-7B and LLaMA-3.1-8B) on two datasets (RGB_zh and RGB_en). Each model is evaluated across two metrics: **Answer Accuracy** (y-axis: 0–1.0) and **Refusal Rate** (y-axis: 0–0.30), with context provided in 10-chunk increments. Categories include "no context," "0 pos," "1 pos," and "5 pos" context chunks. A legend maps colors to knowledge levels: **unknown** (blue), **weakly known** (orange), **maybe known** (green), and **highly known** (red).
---
### Components/Axes
1. **X-Axis (Context Chunks)**:
- Categories: "no context," "0 pos," "1 pos," "5 pos"
- Position: Bottom of both charts
2. **Y-Axes**:
- **Answer Accuracy**: 0–1.0 (left side of both charts)
- **Refusal Rate**: 0–0.30 (right side of both charts)
3. **Legends**:
- Colors: Blue (unknown), Orange (weakly known), Green (maybe known), Red (highly known)
- Position: Right side of both charts
4. **Models/Datasets**:
- Top-left: Qwen-2.5-7B on RGB_zh
- Bottom-left: LLaMA-3.1-8B on RGB_en
---
### Detailed Analysis
#### Answer Accuracy (Left Charts)
- **Qwen-2.5-7B (RGB_zh)**:
- **No context**: Highest accuracy for "highly known" (red, ~0.95), lowest for "unknown" (blue, ~0.05).
- **0 pos**: Accuracy drops for "unknown" (~0.15) and "weakly known" (~0.25), but "highly known" remains high (~0.85).
- **1 pos**: "Unknown" accuracy rises sharply (~0.7), "weakly known" (~0.8), and "highly known" (~0.9).
- **5 pos**: All categories converge near 0.9–1.0, with "unknown" (~0.9) and "weakly known" (~0.95) showing the most improvement.
- **LLaMA-3.1-8B (RGB_en)**:
- **No context**: "Highly known" accuracy peaks (~0.95), "unknown" lowest (~0.1).
- **0 pos**: "Unknown" accuracy drops to ~0.2, "weakly known" (~0.3), "highly known" (~0.85).
- **1 pos**: "Unknown" jumps to ~0.8, "weakly known" (~0.9), "highly known" (~0.95).
- **5 pos**: All categories reach ~0.9–1.0, with "unknown" (~0.95) and "weakly known" (~0.98) leading.
#### Refusal Rate (Right Charts)
- **Qwen-2.5-7B (RGB_zh)**:
- **No context**: Highest refusal rate for "highly known" (~0.25), lowest for "unknown" (~0.05).
- **0 pos**: "Highly known" refusal rate drops to ~0.15, "unknown" rises to ~0.1.
- **1 pos**: "Highly known" refusal rate plummets to ~0.05, "unknown" remains ~0.1.
- **5 pos**: All categories below 0.05, with "highly known" near 0.
- **LLaMA-3.1-8B (RGB_en)**:
- **No context**: "Highly known" refusal rate peaks (~0.2), "unknown" lowest (~0.05).
- **0 pos**: "Highly known" refusal rate drops to ~0.1, "unknown" rises to ~0.07.
- **1 pos**: "Highly known" refusal rate falls to ~0.03, "unknown" remains ~0.07.
- **5 pos**: All categories below 0.05, with "highly known" near 0.
---
### Key Observations
1. **Context Improves Accuracy**:
- Both models show significant accuracy gains with increasing context chunks, especially for "unknown" and "weakly known" categories.
- Qwen-2.5-7B demonstrates sharper improvements in "unknown" accuracy (e.g., ~0.15 → ~0.9 with 5 pos context).
2. **Refusal Rates Decrease with Context**:
- Refusal rates for "highly known" categories drop sharply as context increases (e.g., Qwen: ~0.25 → ~0.05 with 5 pos context).
- LLaMA-3.1-8B maintains lower refusal rates overall but follows the same trend.
3. **Model Performance Differences**:
- Qwen-2.5-7B generally achieves higher accuracy for "unknown" categories with context.
- LLaMA-3.1-8B has slightly lower refusal rates for "highly known" categories without context.
---
### Interpretation
The data suggests that **contextual augmentation** significantly enhances model performance across knowledge levels. For both models:
- **Answer Accuracy**: Providing context (even minimal) reduces performance gaps between knowledge levels. "Unknown" categories benefit most from context, closing the gap with "highly known" categories.
- **Refusal Rate**: Models are less likely to refuse answers when given context, particularly for "highly known" categories. This implies that context helps models avoid overconfidence in uncertain scenarios.
- **Model-Specific Behavior**: Qwen-2.5-7B shows stronger improvements in "unknown" accuracy, while LLaMA-3.1-8B maintains lower refusal rates for "highly known" categories. These differences may stem from architectural design or training data biases.
The charts highlight the importance of context in balancing accuracy and refusal behavior, with implications for deploying models in low-resource or ambiguous scenarios.