## Token Retention Methods Diagram
### Overview
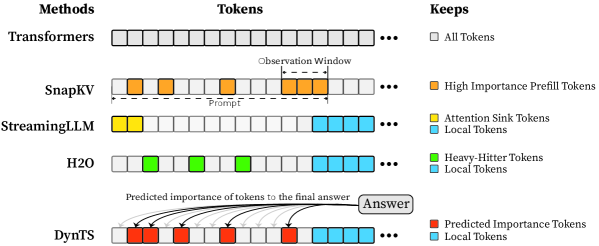
The image is a diagram illustrating different methods for token retention in language models. It compares Transformers, SnapKV, StreamingLLM, H2O, and DynTS, showing which tokens each method keeps based on different criteria.
### Components/Axes
* **Methods (Left Column):** Lists the different language model methods being compared: Transformers, SnapKV, StreamingLLM, H2O, and DynTS.
* **Tokens (Top Row):** Represents the sequence of tokens processed by each method. Each token is represented by a square.
* **Keeps (Right Column):** A legend explaining the color-coding used to indicate which tokens are kept by each method.
* White: All Tokens
* Orange: High Importance Prefill Tokens
* Yellow: Attention Sink Tokens
* Light Blue: Local Tokens
* Green: Heavy-Hitter Tokens
* Red: Predicted Importance Tokens
### Detailed Analysis
* **Transformers:** All tokens are kept (represented by white squares).
* **SnapKV:** Keeps some tokens as "High Importance Prefill Tokens" (orange squares) within a "Prompt" region. An "Observation Window" is also indicated. The remaining tokens are gray, implying they are not retained.
* **StreamingLLM:** Keeps a few "Attention Sink Tokens" (yellow squares) at the beginning, followed by "Local Tokens" (light blue squares).
* **H2O:** Keeps some "Heavy-Hitter Tokens" (green squares) and then "Local Tokens" (light blue squares).
* **DynTS:** Keeps "Predicted Importance Tokens" (red squares) and "Local Tokens" (light blue squares). Arrows point from the red and gray tokens to a box labeled "Answer," indicating the predicted importance of tokens to the final answer.
### Key Observations
* Transformers retain all tokens, while the other methods selectively retain tokens based on different criteria.
* SnapKV focuses on retaining tokens from the prompt.
* StreamingLLM and H2O retain a combination of specific token types (Attention Sink, Heavy-Hitter) and local tokens.
* DynTS retains tokens based on their predicted importance to the final answer.
### Interpretation
The diagram illustrates different strategies for managing and retaining tokens in language models. The methods vary in their approach, with some focusing on retaining important tokens from the prompt (SnapKV), others on specific token types (StreamingLLM, H2O), and others on predicted importance to the final answer (DynTS). The choice of method likely depends on the specific application and the trade-off between computational cost and performance. The diagram highlights the evolution from retaining all tokens (Transformers) to more selective retention strategies.