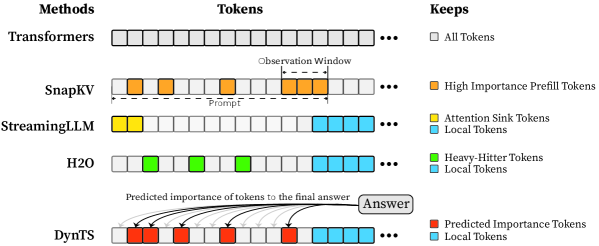
\n
## Diagram: Token Selection Strategies in Language Model Methods
### Overview
This diagram illustrates and compares five different methods for processing and retaining tokens from an input prompt in large language models. It visually demonstrates how each method selects which tokens to keep for computation, highlighting strategies for efficiency and context management. The diagram is structured as a table with rows for each method and columns for the method name, a visual representation of its token sequence, and a legend explaining the token types.
### Components/Axes
The diagram is organized into three main columns:
1. **Methods (Left Column):** Lists the five methods being compared: `Transformers`, `SnapKV`, `StreamingLLM`, `H2O`, and `DynTS`.
2. **Tokens (Center Column):** Displays a horizontal sequence of squares representing tokens for each method. The sequence is truncated with an ellipsis (`...`) on the right, indicating a continuing sequence. A dashed box labeled `Observation Window` is shown within the `SnapKV` row.
3. **Keeps (Right Column / Legend):** A key that maps colors to the type of token each method retains.
* **White Square:** `All Tokens`
* **Orange Square:** `High Importance Prefill Tokens`
* **Yellow Square:** `Attention Sink Tokens`
* **Light Blue Square:** `Local Tokens`
* **Green Square:** `Heavy-Hitter Tokens`
* **Red Square:** `Predicted Importance Tokens`
### Detailed Analysis
The diagram details the token retention strategy for each method:
* **Transformers:**
* **Visual Trend:** The entire token sequence is composed of white squares.
* **Data Points/Strategy:** Retains **All Tokens** from the prompt for processing. This is the baseline, full-context approach.
* **SnapKV:**
* **Visual Trend:** The sequence contains a mix of white and orange squares. A dashed box labeled `Observation Window` encloses a cluster of orange squares towards the right side of the visible sequence. A label `Prompt` points to the beginning of the sequence.
* **Data Points/Strategy:** Selectively keeps **High Importance Prefill Tokens** (orange). The `Observation Window` suggests these important tokens are identified within a specific segment of the prompt. The remaining tokens (white) are presumably discarded or not used for the key-value cache.
* **StreamingLLM:**
* **Visual Trend:** The sequence starts with a few yellow squares on the far left, followed by white squares, and ends with a block of light blue squares on the far right.
* **Data Points/Strategy:** Keeps two types of tokens: **Attention Sink Tokens** (yellow) from the very beginning of the sequence and **Local Tokens** (light blue) from the most recent part of the sequence. The middle tokens (white) are not retained.
* **H2O (Heavy-Hitter Oracle):**
* **Visual Trend:** The sequence shows green squares interspersed among white squares in the first half, followed by a block of light blue squares at the end.
* **Data Points/Strategy:** Keeps **Heavy-Hitter Tokens** (green), which are likely tokens that receive high attention scores, scattered throughout the prompt, and **Local Tokens** (light blue) from the recent context.
* **DynTS (Dynamic Token Selection):**
* **Visual Trend:** The sequence begins with red squares, followed by white squares, and ends with light blue squares. Curved arrows originate from the red squares and point to a box labeled `Answer`. Text above the arrows reads: `Predicted importance of tokens to the final answer`.
* **Data Points/Strategy:** Keeps **Predicted Importance Tokens** (red) and **Local Tokens** (light blue). The arrows indicate that the red tokens are dynamically selected based on a model's prediction of their importance for generating the final `Answer`.
### Key Observations
1. **Progression of Selectivity:** There is a clear evolution from the `Transformers` method (keeping everything) to increasingly selective strategies (`SnapKV`, `StreamingLLM`, `H2O`, `DynTS`) that aim to reduce computational load by retaining only a subset of tokens.
2. **Common Element:** Four of the five methods (all except `Transformers`) explicitly retain **Local Tokens** (light blue) from the end of the sequence, underscoring the importance of recent context.
3. **Diverse Selection Criteria:** The methods use different heuristics to select non-local tokens: fixed position (`StreamingLLM`'s attention sinks), attention scores (`H2O`'s heavy-hitters), importance within a window (`SnapKV`), or predicted relevance to the output (`DynTS`).
4. **Spatial Layout:** The `Observation Window` in `SnapKV` is positioned in the center-right of its token sequence. The `Answer` box for `DynTS` is placed to the right of its token sequence, with arrows creating a visual flow from selected tokens to the output.
### Interpretation
This diagram serves as a technical comparison of context window management techniques in efficient language model inference. It demonstrates the core challenge: balancing the need for long-context understanding with the computational cost of processing every token.
* **What the data suggests:** The field is moving beyond simply truncating context (which would be represented by keeping only local tokens) towards more intelligent, dynamic selection mechanisms. Methods like `DynTS` represent a shift towards task-aware processing, where token retention is directly tied to the goal of generating a correct answer.
* **How elements relate:** The `Tokens` column visually contrasts the "full" sequence of `Transformers` with the "sparse" or "filtered" sequences of the other methods. The `Keeps` legend is essential for decoding the strategy behind each pattern. The `Observation Window` and `Answer` annotations provide crucial context for understanding the operational logic of `SnapKV` and `DynTS`, respectively.
* **Notable patterns/anomalies:** The most striking pattern is the universal retention of local tokens. This implies that regardless of the selection strategy for earlier context, the most recent information is consistently deemed critical. The `DynTS` method is unique in its explicit, goal-oriented selection mechanism, visualized by the predictive arrows, suggesting a more sophisticated, possibly model-driven approach compared to the heuristic-based methods above it.