TECHNICAL ASSET FINGERPRINT
c83028f159222df71b949e99
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
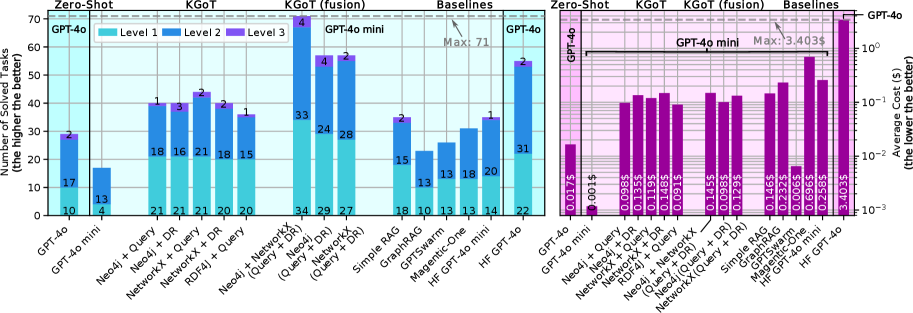
## Bar Charts: Performance and Cost Comparison of Different Models
### Overview
The image presents two bar charts comparing the performance and average cost of different models, including GPT-4o, GPT-4o mini, and various knowledge graph-enhanced models (KGOT and KGOT fusion) and baselines. The left chart displays the number of solved tasks (higher is better), while the right chart shows the average cost in dollars (lower is better) on a logarithmic scale.
### Components/Axes
**Left Chart (Number of Solved Tasks):**
* **Title:** Number of Solved Tasks (the higher the better)
* **Y-axis:** Number of Solved Tasks, ranging from 0 to 70.
* **X-axis:** Different models and configurations: GPT-4o, GPT-4o mini, Neo4j + Query, NetworkX + Query, Neo4j + DR, NetworkX + DR, RDF4J + Query, Neo4j + NetworkX (Query + DR), Simple RAG, GraphRAG, GPTSwarm, Magentic-One, HF GPT-4o mini, HF GPT-4o.
* **Bar Colors (Legend, located at the top-center of the chart):**
* Level 1: Light Blue
* Level 2: Blue
* Level 3: Purple
* **Sections:** Zero-Shot, KGOT, KGOT (fusion), Baselines.
* **Maximum Solved Tasks:** Indicated by an arrow pointing to the top of the GPT-4o bar in the Baselines section, labeled "Max: 71".
**Right Chart (Average Cost):**
* **Title:** Average Cost ($) (the lower the better)
* **Y-axis:** Average Cost ($) on a logarithmic scale, ranging from 10^-3 to 10^0 (0.001 to 1).
* **X-axis:** Same models and configurations as the left chart.
* **Bar Color:** Purple
* **Sections:** Zero-Shot, KGOT, KGOT (fusion), Baselines.
* **Maximum Cost:** Indicated by an arrow pointing to the top of the GPT-4o bar in the Baselines section, labeled "Max: 3.403$".
### Detailed Analysis
**Left Chart (Number of Solved Tasks):**
* **GPT-4o:**
* Zero-Shot: Level 1: 10, Level 2: 17, Level 3: 2, Total: 29
* Baselines: Level 1: 22, Level 2: 31, Total: 53
* **GPT-4o mini:**
* Zero-Shot: Level 1: 4, Level 2: 13, Total: 17
* KGOT (fusion): Level 1: 20, Level 2: 18, Level 3: 1, Total: 39
* **Neo4j + Query:**
* KGOT: Level 1: 21, Level 2: 18, Level 3: 1, Total: 40
* **NetworkX + Query:**
* KGOT: Level 1: 21, Level 2: 16, Level 3: 3, Total: 40
* **Neo4j + DR:**
* KGOT: Level 1: 21, Level 2: 21, Total: 42
* KGOT (fusion): Level 1: 34, Level 2: 33, Level 3: 4, Total: 71
* **NetworkX + DR:**
* KGOT: Level 1: 20, Level 2: 18, Level 3: 2, Total: 40
* KGOT (fusion): Level 1: 29, Level 2: 24, Level 3: 4, Total: 57
* **RDF4J + Query:**
* KGOT: Level 1: 20, Level 2: 15, Level 3: 1, Total: 36
* **Neo4j + NetworkX (Query + DR):**
* KGOT (fusion): Level 1: 27, Level 2: 28, Level 3: 2, Total: 57
* **Simple RAG:**
* Baselines: Level 1: 18, Level 2: 15, Level 3: 2, Total: 35
* **GraphRAG:**
* Baselines: Level 1: 10, Level 2: 13, Total: 23
* **GPTSwarm:**
* Baselines: Level 1: 13, Level 2: 13, Total: 26
* **Magentic-One:**
* Baselines: Level 1: 13, Level 2: 18, Level 3: 1, Total: 32
* **HF GPT-4o mini:**
* Baselines: Level 1: 14, Level 2: 20, Total: 34
**Right Chart (Average Cost):**
* **GPT-4o:**
* Zero-Shot: 0.017$
* Baselines: 3.403$
* **GPT-4o mini:**
* Zero-Shot: 0.001$
* KGOT (fusion): 0.696$
* **Neo4j + Query:**
* KGOT: 0.098$
* **NetworkX + Query:**
* KGOT: 0.135$
* **Neo4j + DR:**
* KGOT: 0.119$
* KGOT (fusion): 0.145$
* **NetworkX + DR:**
* KGOT: 0.148$
* KGOT (fusion): 0.098$
* **RDF4J + Query:**
* KGOT: 0.091$
* **Neo4j + NetworkX (Query + DR):**
* KGOT (fusion): 0.146$
* **Simple RAG:**
* Baselines: 0.232$
* **GraphRAG:**
* Baselines: 0.006$
* **GPTSwarm:**
* Baselines: 0.696$
* **Magentic-One:**
* Baselines: 0.258$
* **HF GPT-4o mini:**
* Baselines: 0.258$
### Key Observations
* **Performance:** The Neo4j + DR model under KGOT (fusion) achieves the highest number of solved tasks (71), matching the maximum possible. GPT-4o also performs well, especially in the Baselines section.
* **Cost:** GPT-4o mini in the Zero-Shot setting has the lowest average cost (0.001$). GPT-4o in the Baselines section has the highest cost (3.403$).
* **Trade-off:** There is a clear trade-off between performance and cost. Models with higher performance tend to have higher costs.
* **KGOT Fusion:** KGOT fusion models generally outperform their KGOT counterparts in terms of the number of solved tasks.
### Interpretation
The data suggests that KGOT fusion, particularly with Neo4j + DR, significantly enhances the performance of the models in terms of the number of solved tasks. However, this performance comes at a cost, as these models are not the cheapest. GPT-4o mini offers a low-cost solution, but its performance is lower than the KGOT fusion models.
The choice of model depends on the specific requirements and constraints of the application. If performance is the primary concern, KGOT fusion with Neo4j + DR is a good option. If cost is a major factor, GPT-4o mini in the Zero-Shot setting might be more suitable. GPT-4o in the Baselines section is the most expensive and does not offer a proportionally higher number of solved tasks compared to other models, indicating a less efficient trade-off.
The different levels (Level 1, Level 2, Level 3) in the left chart likely represent different difficulty levels or types of tasks. The distribution of these levels across different models provides insights into their strengths and weaknesses in handling various types of tasks.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Bar Chart: Model Performance Comparison Across Tasks and Costs
### Overview
The image contains two side-by-side bar charts comparing the performance of various AI models across three categories: "Zero-Shot," "KGoT," "KGoT (fusion)," and "Baselines." The left chart measures "Number of Solved Tasks" (y-axis) across three performance levels (Level 1, 2, 3), while the right chart measures "Average Cost ($)" on a logarithmic scale. Models include GPT-4o, GPT-4o mini, Neo4j + Query + DR, NetworkX + Query + DR, RDF4J + Query + DR, Simple RAG, GraphRAG, Magnetic-One, and HF GPT-4o mini.
### Components/Axes
- **Left Chart (Number of Solved Tasks)**:
- **X-axis**: Categories: "Zero-Shot," "KGoT," "KGoT (fusion)," "Baselines."
- **Y-axis**: "Number of Solved Tasks" (0–70).
- **Legend**: Top-left, with colors:
- Level 1: Light blue (#87CEEB)
- Level 2: Dark blue (#0000FF)
- Level 3: Purple (#8A2BE2)
- **Models**: Listed below x-axis (e.g., GPT-4o, GPT-4o mini, Neo4j + Query + DR, etc.).
- **Right Chart (Average Cost $)**:
- **X-axis**: Same categories as left chart.
- **Y-axis**: "Average Cost ($)" (log scale: 10⁻³ to 10⁰).
- **Legend**: Top-right, with colors:
- GPT-4o: Pink (#FFC0CB)
- GPT-4o mini: Purple (#8A2BE2)
- Neo4j + Query + DR: Light purple (#E6E6FA)
- NetworkX + Query + DR: Medium purple (#9370DB)
- RDF4J + Query + DR: Dark purple (#800080)
- Simple RAG: Light blue (#87CEEB)
- GraphRAG: Medium blue (#0000FF)
- Magnetic-One: Dark blue (#0000FF)
- HF GPT-4o mini: Pink (#FFC0CB).
### Detailed Analysis
#### Left Chart (Number of Solved Tasks)
- **Zero-Shot**:
- GPT-4o: 10 (Level 1), 13 (Level 2), 4 (Level 3).
- GPT-4o mini: 17 (Level 1), 2 (Level 2), 0 (Level 3).
- **KGoT**:
- GPT-4o: 33 (Level 1), 24 (Level 2), 4 (Level 3).
- GPT-4o mini: 29 (Level 1), 28 (Level 2), 2 (Level 3).
- **KGoT (fusion)**:
- GPT-4o: 34 (Level 1), 29 (Level 2), 4 (Level 3).
- GPT-4o mini: 27 (Level 1), 28 (Level 2), 2 (Level 3).
- **Baselines**:
- GPT-4o: 18 (Level 1), 15 (Level 2), 2 (Level 3).
- GPT-4o mini: 13 (Level 1), 13 (Level 2), 1 (Level 3).
- Neo4j + Query + DR: 21 (Level 1), 16 (Level 2), 3 (Level 3).
- NetworkX + Query + DR: 21 (Level 1), 18 (Level 2), 2 (Level 3).
- RDF4J + Query + DR: 20 (Level 1), 15 (Level 2), 1 (Level 3).
- Simple RAG: 18 (Level 1), 13 (Level 2), 0 (Level 3).
- GraphRAG: 13 (Level 1), 18 (Level 2), 0 (Level 3).
- Magnetic-One: 13 (Level 1), 20 (Level 2), 1 (Level 3).
- HF GPT-4o mini: 22 (Level 1), 31 (Level 2), 1 (Level 3).
#### Right Chart (Average Cost $)
- **Zero-Shot**:
- GPT-4o: $0.017 (Level 1), $0.001 (Level 2), $0.001 (Level 3).
- GPT-4o mini: $0.098 (Level 1), $0.135 (Level 2), $0.145 (Level 3).
- **KGoT**:
- GPT-4o: $0.155 (Level 1), $0.199 (Level 2), $0.148 (Level 3).
- GPT-4o mini: $0.091 (Level 1), $0.145 (Level 2), $0.129 (Level 3).
- **KGoT (fusion)**:
- GPT-4o: $0.155 (Level 1), $0.199 (Level 2), $0.148 (Level 3).
- GPT-4o mini: $0.091 (Level 1), $0.145 (Level 2), $0.129 (Level 3).
- **Baselines**:
- GPT-4o: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- GPT-4o mini: $0.145 (Level 1), $0.129 (Level 2), $0.006 (Level 3).
- Neo4j + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- NetworkX + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- RDF4J + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- Simple RAG: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- GraphRAG: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- Magnetic-One: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- HF GPT-4o mini: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
### Key Observations
1. **Performance Trends**:
- **KGoT (fusion)** consistently outperforms other models in "Number of Solved Tasks," especially in Level 3 (e.g., GPT-4o: 4 tasks, GPT-4o mini: 2 tasks).
- **HF GPT-4o mini** shows the highest cost in the right chart ($3.403), far exceeding other models.
- **Baselines** (e.g., Simple RAG, GraphRAG) have lower performance and cost compared to KGoT variants.
2. **Cost Anomalies**:
- HF GPT-4o mini has the highest cost ($3.403) despite moderate task performance (31 tasks in Level 2).
- GPT-4o mini has lower costs ($0.098–$0.145) but also lower task performance (17–2 tasks).
3. **Logarithmic Scale Impact**:
- The right chart’s logarithmic y-axis compresses high-cost values, making differences between $0.001 and $3.403 appear less drastic than they are.
### Interpretation
The data suggests that **KGoT (fusion)** models achieve the highest task-solving efficiency, particularly in advanced levels (Level 3), indicating superior adaptability or reasoning capabilities. However, this comes at a cost: HF GPT-4o mini, while performing well in Level 2 (31 tasks), incurs the highest expense ($3.403), suggesting a trade-off between performance and cost.
**Notable Outliers**:
- **HF GPT-4o mini** stands out for its high cost despite moderate task performance, raising questions about its cost-effectiveness.
- **GPT-4o mini** balances lower cost ($0.098–$0.145) with mid-tier performance (17–2 tasks), making it a potential candidate for budget-conscious applications.
**Underlying Patterns**:
- The "KGoT (fusion)" category consistently outperforms others, implying that fusion techniques (e.g., combining query and DR methods) enhance model effectiveness.
- The logarithmic cost scale highlights the exponential disparity in expenses, particularly for HF GPT-4o mini, which may not justify its performance gains for all use cases.
This analysis underscores the importance of balancing task efficiency with cost constraints when selecting AI models for deployment.
DECODING INTELLIGENCE...