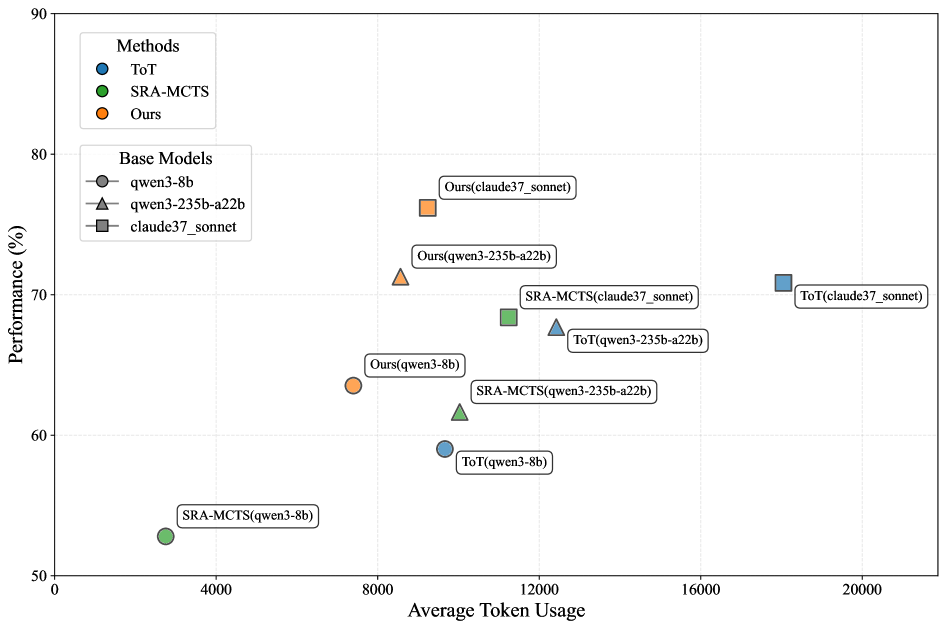
## Scatter Plot: Performance vs. Average Token Usage
### Overview
The image is a scatter plot comparing the performance (in percentage) of different methods (ToT, SRA-MCTS, and Ours) against their average token usage. The data points are further categorized by the base models used (qwen3-8b, qwen3-235b-a22b, and claude37_sonnet).
### Components/Axes
* **Title:** There is no explicit title.
* **X-axis:** Average Token Usage, ranging from 0 to 20000, with gridlines at intervals of 4000.
* **Y-axis:** Performance (%), ranging from 50 to 90, with gridlines at intervals of 10.
* **Legend (Top-Left):**
* **Methods:**
* Blue circle: ToT
* Green circle: SRA-MCTS
* Orange circle: Ours
* **Base Models:**
* Gray circle: qwen3-8b
* Gray triangle: qwen3-235b-a22b
* Gray square: claude37\_sonnet
### Detailed Analysis
The data points are scattered across the plot, each representing a specific method and base model combination. The position of each point indicates its performance and average token usage.
* **ToT (Blue):**
* ToT(qwen3-8b): Performance ~60%, Token Usage ~10000
* ToT(qwen3-235b-a22b): Performance ~68%, Token Usage ~13000
* ToT(claude37\_sonnet): Performance ~70%, Token Usage ~19000
* Trend: As the base model changes from qwen3-8b to qwen3-235b-a22b to claude37_sonnet, both performance and token usage increase.
* **SRA-MCTS (Green):**
* SRA-MCTS(qwen3-8b): Performance ~53%, Token Usage ~3000
* SRA-MCTS(qwen3-235b-a22b): Performance ~63%, Token Usage ~11000
* SRA-MCTS(claude37\_sonnet): Performance ~69%, Token Usage ~12000
* Trend: As the base model changes from qwen3-8b to qwen3-235b-a22b to claude37_sonnet, both performance and token usage increase.
* **Ours (Orange):**
* Ours(qwen3-8b): Performance ~64%, Token Usage ~7500
* Ours(qwen3-235b-a22b): Performance ~71%, Token Usage ~9000
* Ours(claude37\_sonnet): Performance ~75%, Token Usage ~9000
* Trend: As the base model changes from qwen3-8b to qwen3-235b-a22b to claude37_sonnet, performance increases, but token usage remains relatively stable.
### Key Observations
* The "Ours" method generally achieves higher performance with lower token usage compared to "ToT" and "SRA-MCTS" when using the same base model.
* Using the "claude37\_sonnet" base model generally results in higher performance but also higher token usage across all methods.
* SRA-MCTS with qwen3-8b has the lowest token usage and performance.
### Interpretation
The scatter plot visualizes the trade-off between performance and token usage for different methods and base models. The "Ours" method appears to be more efficient, achieving better performance with fewer tokens. The choice of base model significantly impacts both performance and token usage, with "claude37\_sonnet" generally leading to higher performance at the cost of increased token consumption. The data suggests that optimizing the method and base model selection is crucial for balancing performance and computational cost.