\n
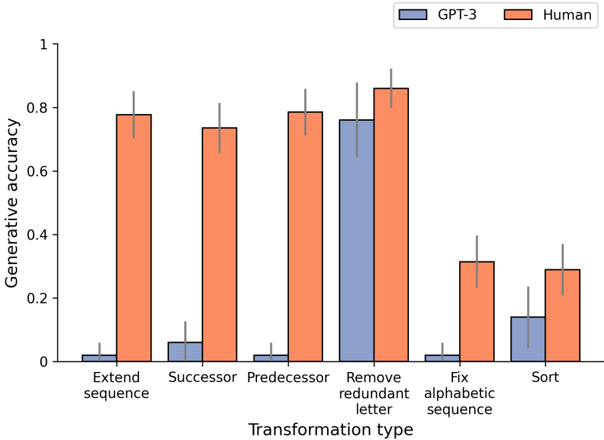
## Bar Chart: Generative Accuracy of GPT-3 vs. Human for Transformation Types
### Overview
This bar chart compares the generative accuracy of GPT-3 and humans across six different sequence transformation types. The y-axis represents generative accuracy, ranging from 0 to 1. The x-axis represents the transformation type. Each transformation type has two bars: one for GPT-3 (blue) and one for Human (orange). Error bars are present on top of each bar, indicating the variability in accuracy.
### Components/Axes
* **X-axis Title:** Transformation type
* **X-axis Categories:** Extend sequence, Successor, Predecessor, Remove redundant letter, Fix alphabetic sequence, Sort
* **Y-axis Title:** Generative accuracy
* **Y-axis Scale:** 0 to 1, with increments of 0.2
* **Legend:**
* GPT-3 (Blue)
* Human (Orange)
### Detailed Analysis
Let's analyze each transformation type individually, noting the approximate values based on the bar heights and error bars.
1. **Extend sequence:**
* GPT-3: Approximately 0.05 ± 0.02
* Human: Approximately 0.75 ± 0.05
2. **Successor:**
* GPT-3: Approximately 0.08 ± 0.03
* Human: Approximately 0.70 ± 0.05
3. **Predecessor:**
* GPT-3: Approximately 0.05 ± 0.02
* Human: Approximately 0.75 ± 0.05
4. **Remove redundant letter:**
* GPT-3: Approximately 0.72 ± 0.05
* Human: Approximately 0.85 ± 0.05
5. **Fix alphabetic sequence:**
* GPT-3: Approximately 0.03 ± 0.02
* Human: Approximately 0.30 ± 0.05
6. **Sort:**
* GPT-3: Approximately 0.18 ± 0.05
* Human: Approximately 0.25 ± 0.05
### Key Observations
* Humans consistently outperform GPT-3 across all transformation types.
* GPT-3 performs particularly poorly on "Extend sequence", "Successor", "Predecessor", and "Fix alphabetic sequence" tasks, with accuracy values close to 0.
* The largest difference in performance between GPT-3 and humans is observed in the "Extend sequence" task.
* The smallest difference in performance is observed in the "Remove redundant letter" task.
* Error bars indicate that the human performance is more consistent than GPT-3's performance across most tasks.
### Interpretation
The data suggests that GPT-3 struggles with tasks requiring a deeper understanding of sequence structure and logical reasoning, such as extending sequences, identifying successors/predecessors, and fixing alphabetic order. Humans, on the other hand, demonstrate a strong ability in these areas.
The "Remove redundant letter" task shows a smaller performance gap, potentially indicating that this task relies more on pattern recognition and less on complex reasoning, which GPT-3 can handle relatively well.
The consistent outperformance of humans highlights the limitations of current language models in tasks that require human-level cognitive abilities. The error bars suggest that human performance is more reliable, while GPT-3's accuracy is more variable, potentially due to its reliance on statistical patterns rather than true understanding. The data suggests that GPT-3 is better at identifying and removing redundancies than it is at generating or manipulating sequences based on underlying rules.