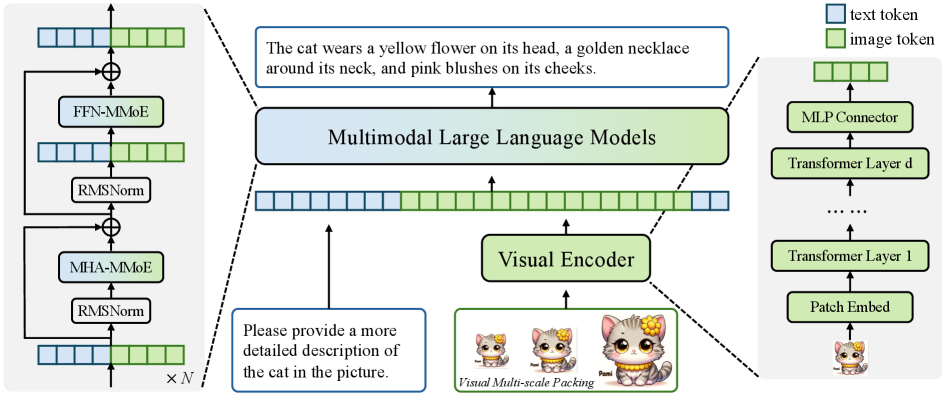
## Diagram: Multimodal Large Language Model Architecture
### Overview
The image presents a diagram of a multimodal large language model architecture. It illustrates how text and image data are processed and integrated within the model. The diagram includes components for text processing, image encoding, and multimodal fusion.
### Components/Axes
* **Legend:** Located at the top-right of the image.
* Blue square: "text token"
* Green square: "image token"
* **Main Components:**
* **Left Side:** Shows a repeating block of layers labeled "FFN-MMoE", "RMSNorm", "MHA-MMoE", and "RMSNorm", repeated N times.
* **Center:** Depicts the core architecture, including "Multimodal Large Language Models", "Visual Encoder", and input/output text boxes.
* **Right Side:** Shows a series of layers labeled "MLP Connector", "Transformer Layer d", "Transformer Layer 1", and "Patch Embed".
* **Input Text:** "Please provide a more detailed description of the cat in the picture."
* **Input Image:** Three images of a cartoon cat, labeled "Visual Multi-scale Packing" and "Pomi".
* **Output Text:** "The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."
### Detailed Analysis
* **Left Side (Text Processing):**
* A repeating block of layers is shown, with an input of mixed text and image tokens.
* The block consists of:
* "MHA-MMoE" (Multi-Head Attention - Mixture of Experts)
* "RMSNorm" (Root Mean Square Normalization)
* "FFN-MMoE" (Feed Forward Network - Mixture of Experts)
* "RMSNorm" (Root Mean Square Normalization)
* The output of the block is fed back into the input via a skip connection (addition).
* The entire block is repeated N times, as indicated by "x N".
* **Center (Multimodal Fusion):**
* The input text "Please provide a more detailed description of the cat in the picture" is fed into the "Multimodal Large Language Models" block.
* The "Visual Encoder" processes the input images (Visual Multi-scale Packing) and feeds the encoded image tokens into the "Multimodal Large Language Models" block.
* The "Multimodal Large Language Models" block outputs the text "The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."
* **Right Side (Image Processing):**
* The input image of the cat is processed by a "Patch Embed" layer.
* The output of the "Patch Embed" layer is fed into a series of transformer layers, starting with "Transformer Layer 1" and ending with "Transformer Layer d".
* The output of the final transformer layer is fed into an "MLP Connector" layer.
* The output of the "MLP Connector" layer is the image token representation.
### Key Observations
* The diagram illustrates a multimodal model that combines text and image data.
* The model uses a visual encoder to process images and generate image tokens.
* The model uses a repeating block of layers (MHA-MMoE, RMSNorm, FFN-MMoE, RMSNorm) for text processing.
* The model uses transformer layers for image processing.
* The model uses a mixture of experts (MMoE) architecture in both the text and image processing components.
### Interpretation
The diagram illustrates a multimodal large language model designed to generate text descriptions from images. The model takes both text prompts and visual inputs, processes them through separate encoders (text and visual), and then fuses the information to generate a coherent text description. The use of Mixture of Experts (MMoE) suggests that the model can selectively activate different parts of the network based on the input, allowing it to handle a wide range of image and text combinations. The skip connection in the text processing block likely helps with gradient flow during training and allows the model to retain information from earlier layers. The visual multi-scale packing suggests that the model is designed to handle images of different sizes and resolutions.