\n
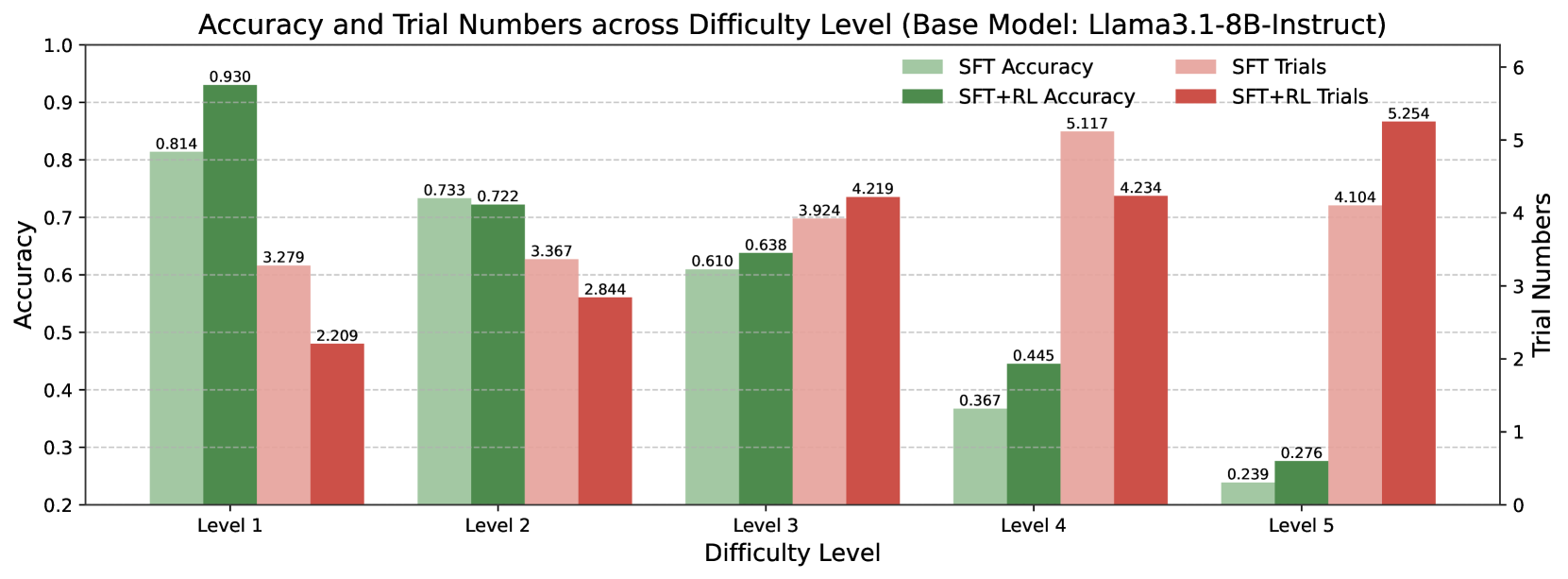
## Grouped Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Llama3.1-8B-Instruct)
### Overview
This is a grouped bar chart comparing the performance of two model training approaches—Supervised Fine-Tuning (SFT) and SFT combined with Reinforcement Learning (SFT+RL)—across five increasing difficulty levels. The chart displays two metrics for each approach: Accuracy (left y-axis) and Trial Numbers (right y-axis). The base model for all evaluations is Llama3.1-8B-Instruct.
### Components/Axes
* **Title:** "Accuracy and Trial Numbers across Difficulty Level (Base Model: Llama3.1-8B-Instruct)"
* **X-Axis (Horizontal):** "Difficulty Level". Categories are discrete: Level 1, Level 2, Level 3, Level 4, Level 5.
* **Primary Y-Axis (Left):** "Accuracy". Scale ranges from 0.2 to 1.0, with major gridlines at 0.1 intervals.
* **Secondary Y-Axis (Right):** "Trial Numbers". Scale ranges from 0 to 6, with major gridlines at integer intervals.
* **Legend (Top-Right Corner):**
* Light Green Bar: "SFT Accuracy"
* Dark Green Bar: "SFT+RL Accuracy"
* Light Red Bar: "SFT Trials"
* Dark Red Bar: "SFT+RL Trials"
### Detailed Analysis
Data is presented in four bars per difficulty level. Values are annotated directly on top of each bar.
**Level 1:**
* **Accuracy:** SFT = 0.814 (light green), SFT+RL = 0.930 (dark green). SFT+RL shows a significant accuracy improvement.
* **Trials:** SFT = 3.279 (light red), SFT+RL = 2.209 (dark red). SFT+RL requires fewer trials.
**Level 2:**
* **Accuracy:** SFT = 0.733 (light green), SFT+RL = 0.722 (dark green). Performance is nearly identical, with SFT slightly higher.
* **Trials:** SFT = 3.367 (light red), SFT+RL = 2.844 (dark red). SFT+RL requires fewer trials.
**Level 3:**
* **Accuracy:** SFT = 0.610 (light green), SFT+RL = 0.638 (dark green). SFT+RL shows a modest accuracy improvement.
* **Trials:** SFT = 3.924 (light red), SFT+RL = 4.219 (dark red). SFT+RL requires more trials.
**Level 4:**
* **Accuracy:** SFT = 0.367 (light green), SFT+RL = 0.445 (dark green). SFT+RL shows a notable accuracy improvement.
* **Trials:** SFT = 5.117 (light red), SFT+RL = 4.234 (dark red). SFT+RL requires fewer trials.
**Level 5:**
* **Accuracy:** SFT = 0.239 (light green), SFT+RL = 0.276 (dark green). SFT+RL shows a small accuracy improvement.
* **Trials:** SFT = 4.104 (light red), SFT+RL = 5.254 (dark red). SFT+RL requires significantly more trials.
### Key Observations
1. **Accuracy Trend:** For both SFT and SFT+RL, accuracy consistently and sharply declines as difficulty increases from Level 1 to Level 5.
2. **Trial Trend:** The number of trials generally increases with difficulty for both methods, though the pattern is less linear than accuracy. The highest trial count for SFT is at Level 4 (5.117), and for SFT+RL is at Level 5 (5.254).
3. **SFT vs. SFT+RL Performance:** SFT+RL achieves higher accuracy than SFT at four out of five difficulty levels (Levels 1, 3, 4, 5). The exception is Level 2, where they are nearly equal.
4. **Trial Efficiency:** The relationship between trial numbers for the two methods is inconsistent. SFT+RL uses fewer trials at Levels 1, 2, and 4, but more trials at Levels 3 and 5.
### Interpretation
The data demonstrates the expected inverse relationship between task difficulty and model accuracy. The core finding is that applying Reinforcement Learning (RL) on top of Supervised Fine-Tuning (SFT) generally improves the model's final accuracy across most difficulty levels for the Llama3.1-8B-Instruct base model.
However, the benefit is not uniform. The most substantial accuracy gain from RL is seen at the easiest (Level 1) and mid-high (Level 4) difficulties. At the highest difficulty (Level 5), the accuracy gain from RL is marginal.
The trial number data suggests a complex relationship between RL and computational cost or exploration. RL does not consistently reduce the number of trials needed. In fact, at the highest difficulty (Level 5), RL requires the most trials of any condition, suggesting the RL process may struggle to find a successful policy for very hard tasks, even if it ultimately yields a slightly better final model. The peak trial count for SFT at Level 4, followed by a drop at Level 5, might indicate a different failure mode or ceiling effect for the SFT-only approach at extreme difficulties.
In summary, SFT+RL is a more accurate training paradigm than SFT alone for this model across a range of difficulties, but its efficiency in terms of trial numbers is highly dependent on the specific difficulty level.