TECHNICAL ASSET FINGERPRINT
cc67e009662d0a7a0051e35b
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
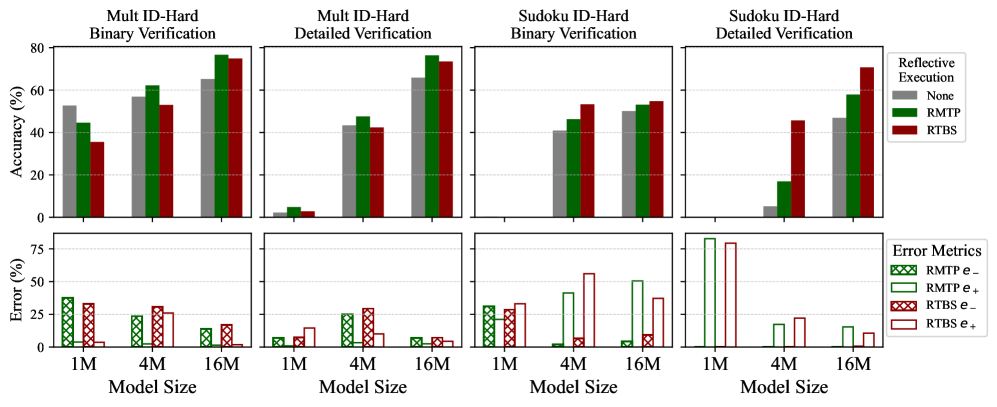
## Bar Charts: Reflective Execution Performance Across Model Sizes
### Overview
The image displays a 2x4 grid of bar charts comparing the performance of different "Reflective Execution" methods on two tasks ("Mult ID-Hard" and "Sudoku ID-Hard") using two verification types ("Binary" and "Detailed"). The top row measures Accuracy (%), and the bottom row measures Error (%). Performance is evaluated across three model sizes: 1M, 4M, and 16M parameters.
### Components/Axes
* **Chart Structure:** 8 individual bar charts arranged in 2 rows and 4 columns.
* **Row 1 (Top):** Y-axis label: **Accuracy (%)**. Scale: 0 to 80.
* **Row 2 (Bottom):** Y-axis label: **Error (%)**. Scale: 0 to 75.
* **X-axis (All Charts):** Label: **Model Size**. Categories: **1M**, **4M**, **16M**.
* **Column Titles (Top Row):**
1. Mult ID-Hard Binary Verification
2. Mult ID-Hard Detailed Verification
3. Sudoku ID-Hard Binary Verification
4. Sudoku ID-Hard Detailed Verification
* **Legends:**
* **Top-Right (Accuracy Charts):** "Reflective Execution" with three categories:
* **None** (Gray bar)
* **RMTP** (Green bar)
* **RTBS** (Red bar)
* **Bottom-Right (Error Charts):** "Error Metrics" with four categories:
* **RMTP e-** (Green bar with cross-hatch pattern)
* **RMTP e+** (Green bar, solid outline)
* **RTBS e-** (Red bar with cross-hatch pattern)
* **RTBS e+** (Red bar, solid outline)
### Detailed Analysis
#### **Row 1: Accuracy (%)**
**Trend Verification:** Across all four tasks, accuracy generally increases with model size for all methods. The "None" (gray) baseline often shows the lowest accuracy, while RMTP (green) and RTBS (red) typically perform better, with their relative performance varying by task.
1. **Mult ID-Hard Binary Verification:**
* **1M:** None ~52%, RMTP ~45%, RTBS ~35%.
* **4M:** None ~58%, RMTP ~62%, RTBS ~53%.
* **16M:** None ~65%, RMTP ~78%, RTBS ~75%.
* *Observation:* RMTP and RTBS overtake "None" at 4M and 16M. RMTP is highest at 16M.
2. **Mult ID-Hard Detailed Verification:**
* **1M:** All methods very low (<5%).
* **4M:** None ~42%, RMTP ~48%, RTBS ~42%.
* **16M:** None ~65%, RMTP ~76%, RTBS ~73%.
* *Observation:* Dramatic improvement from 1M to 4M. RMTP leads at 4M and 16M.
3. **Sudoku ID-Hard Binary Verification:**
* **1M:** None ~40%, RMTP ~45%, RTBS ~53%.
* **4M:** None ~50%, RMTP ~52%, RTBS ~55%.
* **16M:** None ~50%, RMTP ~52%, RTBS ~55%.
* *Observation:* Performance plateaus after 4M. RTBS consistently has a slight edge.
4. **Sudoku ID-Hard Detailed Verification:**
* **1M:** None ~5%, RMTP ~18%, RTBS ~45%.
* **4M:** None ~45%, RMTP ~58%, RTBS ~70%.
* **16M:** No bars visible for "None". RMTP ~58%, RTBS ~70%.
* *Observation:* RTBS shows a very strong lead, especially at 1M and 4M. The "None" method appears to fail completely at 16M (0% accuracy).
#### **Row 2: Error (%)**
**Trend Verification:** Error rates generally decrease with model size. The charts break down errors into "e-" (likely under-execution/omission) and "e+" (likely over-execution/commission) for RMTP and RTBS.
1. **Mult ID-Hard Binary Verification:**
* **1M:** RMTP e- ~38%, RMTP e+ ~35%, RTBS e- ~35%, RTBS e+ ~5%.
* **4M:** RMTP e- ~25%, RMTP e+ ~25%, RTBS e- ~30%, RTBS e+ ~25%.
* **16M:** RMTP e- ~15%, RMTP e+ ~15%, RTBS e- ~18%, RTBS e+ ~15%.
* *Observation:* Errors decrease with scale. At 1M, RTBS has a very low e+ error but high e- error.
2. **Mult ID-Hard Detailed Verification:**
* **1M:** RMTP e- ~8%, RMTP e+ ~5%, RTBS e- ~15%, RTBS e+ ~12%.
* **4M:** RMTP e- ~25%, RMTP e+ ~25%, RTBS e- ~30%, RTBS e+ ~12%.
* **16M:** RMTP e- ~8%, RMTP e+ ~8%, RTBS e- ~8%, RTBS e+ ~5%.
* *Observation:* Error patterns are less consistent. RTBS e+ is often lower than its e- counterpart.
3. **Sudoku ID-Hard Binary Verification:**
* **1M:** RMTP e- ~32%, RMTP e+ ~30%, RTBS e- ~30%, RTBS e+ ~35%.
* **4M:** RMTP e- ~2%, RMTP e+ ~42%, RTBS e- ~8%, RTBS e+ ~58%.
* **16M:** RMTP e- ~5%, RMTP e+ ~52%, RTBS e- ~12%, RTBS e+ ~38%.
* *Observation:* A striking pattern: e+ errors (solid bars) become dominant at 4M and 16M, especially for RMTP, while e- errors (hatched) drop significantly.
4. **Sudoku ID-Hard Detailed Verification:**
* **1M:** RMTP e- ~82%, RMTP e+ ~80%, RTBS e- ~0%, RTBS e+ ~0%.
* **4M:** RMTP e- ~0%, RMTP e+ ~20%, RTBS e- ~0%, RTBS e+ ~22%.
* **16M:** RMTP e- ~0%, RMTP e+ ~18%, RTBS e- ~0%, RTBS e+ ~12%.
* *Observation:* At 1M, RMTP has extremely high e- and e+ errors, while RTBS shows near-zero errors (correlating with its higher accuracy). At larger sizes, e- errors vanish, leaving only e+ errors.
### Key Observations
1. **Scale is Critical:** Performance (accuracy) improves dramatically from 1M to 4M parameters for most tasks, with smaller gains or plateaus from 4M to 16M.
2. **Task Difficulty:** "Detailed Verification" tasks show lower initial accuracy (at 1M) than "Binary Verification" tasks, indicating they are more challenging for smaller models.
3. **Method Superiority:** **RTBS** (red) often achieves the highest accuracy, particularly on the Sudoku tasks. **RMTP** (green) is competitive and sometimes leads on the Mult tasks.
4. **Error Type Shift:** A notable anomaly occurs in the Sudoku Binary Verification error chart, where the dominant error type shifts from a mix at 1M to predominantly **e+** (over-execution) errors at 4M and 16M.
5. **Baseline Failure:** The "None" (no reflective execution) method fails completely (0% accuracy) on the Sudoku Detailed Verification task at 16M, highlighting the necessity of reflective execution for complex tasks at scale.
### Interpretation
This data suggests that **reflective execution mechanisms (RMTP and RTBS) are essential for solving complex, multi-step reasoning tasks**, especially as model scale increases. Their benefit is most pronounced on the harder "Detailed Verification" tasks and the structured "Sudoku" domain.
The shift in error types (from e- to e+) in Sudoku tasks implies that as models grow larger and more capable, their failure mode changes from *failing to attempt* a solution (omission) to *attempting but incorrectly executing* the solution (commission). This is a sign of increased model confidence and capability, but also a need for better execution verification.
The superior performance of RTBS on Sudoku tasks may indicate it is better suited for problems with strict, rule-based logical structures. In contrast, RMTP's strength on the "Mult" tasks might suggest an advantage in more open-ended or multi-faceted reasoning. The complete failure of the baseline at 16M on the hardest task underscores that raw model scale alone is insufficient without structured reasoning scaffolds like reflective execution.
DECODING INTELLIGENCE...